
안녕하세요!!
데이터프레임 2개가 있을때 이 두 데이터프레임을 비교하는 2가지 방법에 대해 알아보겠습니다.
(전제: 두 데이터프레임의 컬럼 이름이 모두 동일하고, 컬럼별로 datatype이 모두 동일해야 비교가 가능합니다.)
데이터프레임의 비교는 주로 서로 다른 과정을 통해 정제된 두 데이터가 서로 어떻게 차이나는지를 볼때 사용됩니다.
예를들어, 회계장부가 각 날짜별로 내 컴퓨터에서 관리가 되고, 회계장부 전체가 서버에서 관리가 되고 있을때, 내 컴퓨터에서 관리되는 회계장부를 취합해서 서버에서 관리되는 회계장부와 비교할때 쓸 수 있는 기술입니다.
* 코드만 필요하신 분을 위한 df1과 df2를 전체 비교하는 코드입니다.
출력 : df1과 df2에 대해 차이나는 행을 출력
df = pd.concat([df1,df2])
df = df.reset_index(drop=True) # 인덱스 초기화
df_grp = df.groupby(df.columns.tolist()) # 전체 열 비교
df_di = df_grp.groups # 딕셔너리로 만들기
idx = [x[0] for x in df_di.values() if len(x) == 1] # 인덱스 검토
df.loc[idx,:] # Same as df.reindex(idx)
해당 코드를 실제 예시와 함께 자세히 설명하겠습니다.
데이터는 titanic 데이터를 사용하겠습니다.
-목차-
1. 비교할 데이터프레임 2개 만들기
2. 부분 비교
3. 전체 비교
1. 비교할 데이터프레임 2개 만들기

df.sample(n=3,random_state=10)* 코드 설명: titanic 정보가 저장된 df에서 랜덤하게 3줄만 뽑아오는 코드입니다. random_state는 랜덤하게 추출해올 때 그 랜덤값이 계속 같은 랜덤값이 추출되도록 랜덤에 상태를 부여하는 파라미터입니다.
이제 비교할 두 데이터프레임을 만들겠습니다.
첫 번째 데이터프레임을 인덱스 초기화하여 df1에 저장합니다.
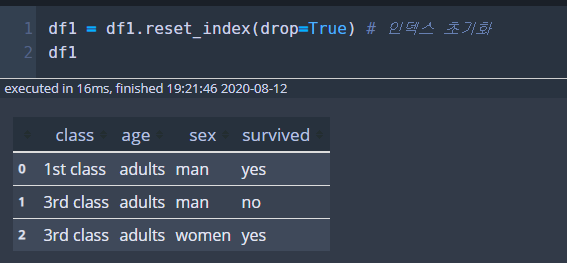
두 번쨰 데이터프레임은 df1을 복사해와서 마지막 줄만 바꿔 df2에 저장하겠습니다.

2. 부분 비교
비교는 4가지 단계를 거쳐 진행됩니다.
첫번째는 비교할 두 데이터프레임 위아래로 붙이기, 두번째는 비교할 열 설정하기, 세번째는 데이터프레임을 딕셔너리로 바꾸기, 네번째는 딕셔너리에서 중복되지 않는 행 보기
1) 비교할 두 데이터프레임 위아래로 붙이기
비교할 두 테이터프레임을 pd.concat을 이용해 위아래로 붙이고 인덱스를 초기화 해줍니다.

2) 비교할 열 설정
부분 비교는 모든 열을 비교하는 것이 아니고, 원하는 열만 선택해서 두 데이터프레임간에 어떤 차이가 있는지 볼때 사용합니다.
아래 예시에서는 age열과 sex열만 가져와 비교할 것입니다.

3) 데이터 프레임을 딕셔너리로
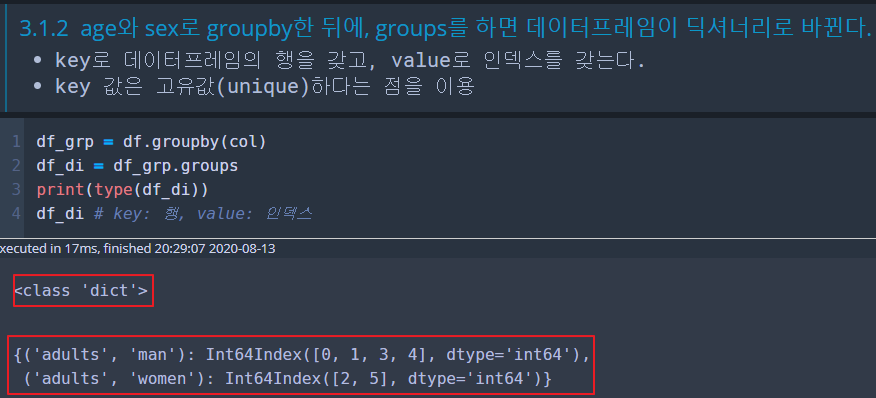
df_grp = df.groupby(col)
df_di = df_grp.groups* 코드 설명:
① df.groupby(col): 비교할 열이 저장된 col로 groupby를 해줍니다. (해당 열에서 같은 값을 갖는 행끼리 그루핑됩니다.)
② df_grp.groups: 그룹화된 df_grp에 groups를 해주면, 행끼리 그루핑된 것을 key로, 그 행들의 인덱스를 values로 갖는 딕셔너리가 생성됩니다.
4) 딕셔너리에서 중복되지 않는 행 보기
위에서 생성된 딕셔너리에는 공통으로 갖는 값에 대해서는 행들의 인덱스가 2개 이상일 것입니다. df1에서 하나, df2에서 하나가 그루핑되었을 것이기 때문입니다.

idx = [x[0] for x in df_di.values() if len(x) == 1]
df.loc[idx,:]*코드 설명:
① [x[0] for x in df_di.values() if len(x) == 1] : df_di 딕셔너리의 values로는 행들의 인덱스가 저장됩니다. 여기서 if len(x)==1을 통해 인덱스의 길이가 1인것을 가져와 그인덱스 값(x[0])을 리스트로 만드는 코드입니다.
② df.loc[idx,:] : 이 코드는 인덱스 값이 리스트로 들어있는 idx를 통해 df에서 해당 인덱스의 행들만 출력하는 코드입니다.
3. 전체 비교
전체 비교 역시 위의 부분비교와 똑같이 진행됩니다. 1가지 차이만 있는데, 그 차이는 비교하는 열이 부분이 아니라 전체라는 점입니다.
즉, 위의 2) 비교할 열 설정에서 아래와 같은 코드를 이용해 전체열을 비교하면 그것이 전체 비교입니다.

전체 열을 담은 리스트 col2를 만들고 뒷 부분은 아래와 같이 진행하면 됩니다.

결과적으로, df1과 df2의 차이나는 마지막 줄만 출력되었습니다.
위의 실습 코드 깃허브를 공유드립니다.
https://github.com/netsus/pandas_practice/blob/master/Pandas_practice_3_compare_dataframe.ipynb
netsus/pandas_practice
Pandas examples in practice. Contribute to netsus/pandas_practice development by creating an account on GitHub.
github.com
이번엔 두 데이터프레임 df1과 df2가 있을때, 비교하고 차이나는 행을 출력하는 방법에 대해 알아보았습니다.
다음에 더 좋은 글로 찾아오겠습니다.
읽어주셔서 감사합니다.
'Data Science & Analysis > Pandas' 카테고리의 다른 글
| [Pandas] 다중 인덱스 엑셀 읽기 및 처리 (Multi Index, Multi Column) (0) | 2020.09.15 |
|---|---|
| [Pandas] 리스트(list) 순서로 데이터프레임 정렬 (0) | 2020.09.14 |
| [Pandas] str.extract, str.contains 정규표현식 사용 (0) | 2020.08.06 |
| [Pandas] 유용한 pandas 기능 4 가지 (컬럼 순서 변경, insert, loc, Groupby) (2) | 2020.07.30 |
| pydataset 이란? 700개 이상의 테스트 데이터 library (0) | 2020.07.23 |