
1. 강의 내용
1️⃣ 추천 시스템 개론
추천 시스템의 정의부터, 개발 시 고려해야 할 점으로 데이터, Task 설정, 목적함수 설계 등을 배웠습니다. 추천 시스템의 분류 체계를 정말 보기 좋게 알려주셨습니다. 외에 평가방법으로 Offline Test와 Online Test 방법을 알려주셨습니다.

2️⃣ CB(Content Based 추천 시스템)과 CF(Collaborative Filtering)의 대분류
콘텐츠 베이스 추천 시스템(CB)의 개념과 다양한 유사도 측정방법 및 예제를 학습했습니다. CB는 크게 Vectorizer와 Similarity로 분류됩니다. Vectorizer는 TF-IDF나 Word2Vec을 이용해 추천할 아이템을 임베딩 벡터로 변환하는 것입니다. Similarity는 자카드 유사도, 유클리드 유사도, 코사인 유사도, 피어슨 상관 계수를 배웠습니다. 다음으로 CF의 대분류인 Memory Based CF와 Model Based CF를 나누어 배웠습니다. Memory Based CF의 개념과 예제를 학습했습니다. UBCF(User Based CF)와 IBCF(Item Based CF)의 장점 한계점 예시를 배웠습니다. Model Based CF에서는 Clustering을 배웠고, 대표적으로 K-Means CF를 배웠습니다.
3️⃣ Model Based CF
Model Based CF 중 Latent Factor(잠재 요인) 기반의 CF를 배웠습니다. SVD(Singlular Value Decomposition)과 MF(Matrix Factorization), ALS(Alternative Least Square)와 Hybrid 추천 시스템을 배웠습니다. 또 다른 Model Based CF인 머신러닝 기반 CF는 NaiveBayse 기법과 GBDT(Gradient Boosting Decision Tree)를 배웠고, GBDT 중 유명한 3가지(XGBoost, LightGBM, CatBoost)를 배웠습니다.
4️⃣ Context Aware Recommend System(CARS)와 딥러닝 기반 추천 시스템
CARS(컨텍스트 기반 추천 시스템)으로는 기존의 MF 한계를 극복한 FM(Factorization Machined)와 FFM(Filed-aware Factorization Machined)를 배웠습니다. 딥러닝 기반 추천 시스템으로는 NCF(Neural Collaborative Filtering), AutoRec, WDN(Wide & Deep Network), DCN(Deep & Cross Network)를 배웠습니다.
5️⃣ 라이브러리를 활용한 Recommender System
Surprise와 Implicit, LightFM, recommenders 라이브러리를 사용해서 추천 시스템을 만드는 방법을 이론과 실습 코드로 간단히 배웠습니다. 해당 라이브러리가 지원하는 데이터의 형태(Explicit, Implicit), Split 방법론(KFlod, Stratified, chorono), 모델과 평가방법을 배웠습니다. 그리고 추천 시스템의 분석 프로세스를 Preprocessing, Model, Evaluation으로 나누어 자세하게 배웠습니다.
6️⃣ Kakao Arena 우승작
카카오 아레나의 추천 시스템 대회에서, 실제 현업의 문제와 데이터를 대회로 진행했던 것의 우승작들의 아이디어와 방법론을 배웠습니다. 2가지 대회를 다루었습니다. 첫 번째는 브런치 글 추천 대회로 30만 명이 60만 개의 글에 대해 1200만 개의 평점을 내린 다양한 데이터를 기반으로 한 대회였습니다. 우승 모델 3가지의 기초 아이디어를 배웠습니다. 두 번째는 멜론의 플레이 리스트 추천 대회로 오디오 웨이브 시그널을 시간별로 잘라 푸리에 변환해 2D 이미지로 제공하는 멜 스펙토 그램 데이터가 인상 깊었습니다. 역시 우승 모델 3가지 기초 아이디어를 배웠습니다.
7️⃣ 비정형 데이터(이미지)를 활용한 추천 시스템
기존 CF 기반 추천 시스템의 근본적인 문제(신규 유저 유입과 유행의 변화)와 이를 해결하기 위한 비정형 데이터 도입을 배웠습니다. 비정형 데이터중 이미지 데이터를 사용하는 딥러닝 기반 추천 시스템을 배웠습니다. 첫 번째 논문은 Image-based Recommendations on Styles and Substitues로, 사람이 상품 이미지를 어떻게 인식하는지 활용하는 이미지 모델이고, 두 번째는 VBPR(VIsual Bayesian Personalized Ranking from Implicit Feedback)로, 제품을 선택할 때 고려하는 시각적 차원을 학습하는 모델로 개인화된 선호 순위를 선정하기 위해 이미지를 활용한 모델을 배웠습니다.
8️⃣ 비정형 데이터(텍스트)를 활용한 추천 시스템
텍스트 데이터를 활용한 추천 시스템은 어떻게 구성되는지, 관련 논문을 학습했습니다. 첫 번째는 Joint Deep Modeling of users and items Using Reviews for Recommendation으로 DeepCoNN 모델을 학습했습니다. 두 번째는 RNN을 활용한 Joint Deep 모델을 학습했습니다. 외에도 정형과 비정형 데이터 모두를 활용한 멀티 모달 딥러닝 추천 시스템을 배웠습니다. 데이콘에서 KNOW 기반 직업 추천 알고리즘 대회의 우승 솔루션이 멀티 모달 딥러닝 추천 시스템중 TabNet을 차용한 것을 통해 해당 구조와 어떻게 차용했는지를 학습했습니다.
2. 피어 세션
1) 일반
이번 주에는 대회 관련 강의와 실습 코드, 미션 코드 등을 공부하고 공유하는 시간을 메인으로 가졌습니다. 진짜 공부량이 너무 많아서 혼자라면 절대 다 못 봤을 양인데, 같이 보면서 공유하고 토의함으로써 겨우 다 소화해낼 수 있었던 것 같습니다. 강의를 거의 다 들은 시점에서 첫 대회를 시작해야 하는데, 이미 다른 팀들은 점수가 꽤 높아 조금 막막했습니다. 하지만 어떻게 대회를 해 나가야 할지 팀원들과 얘기하고 시스템을 갖추는 시간을 갖게 되어 오히려 더 단단한 팀워크를 낼 준비가 된 것 같아 너무 좋았습니다.
2) 코딩 테스트 스터디
이번 주에는 이진 탐색과 관련된 알고리즘을 풀어와 한 문제씩 발표하고 의견을 나누었습니다.
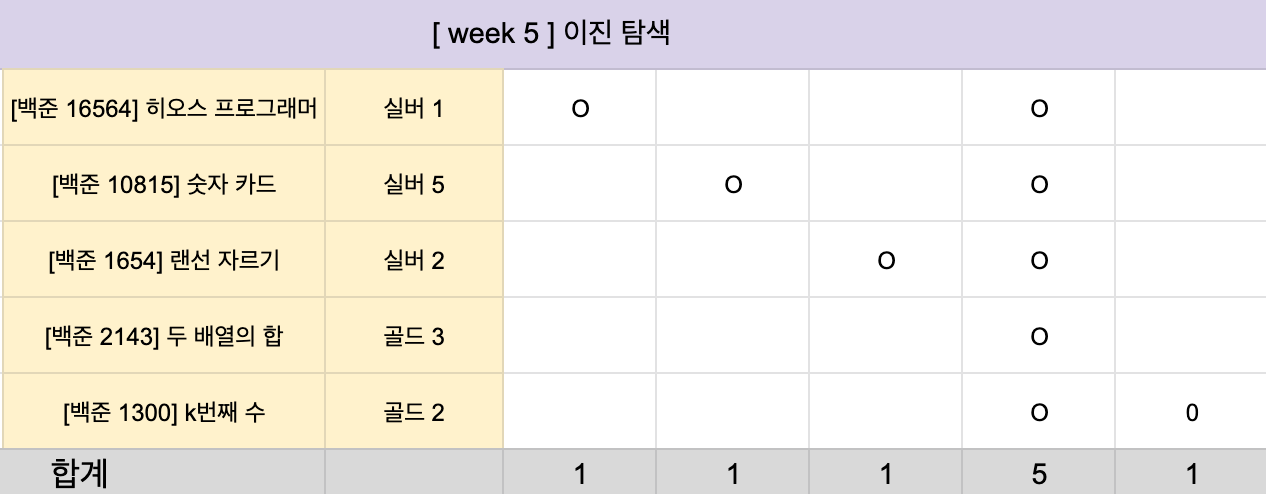
특히, 이진 탐색할 때 특정 문제들에서는 등호(==)를 넣으면 틀리는 경우가 있었는데, 그 부분에 대해 생각해 볼 수 있었던 게 흥미로웠습니다. (히오스 프로그래머 문제와 k 번째 수 문제)
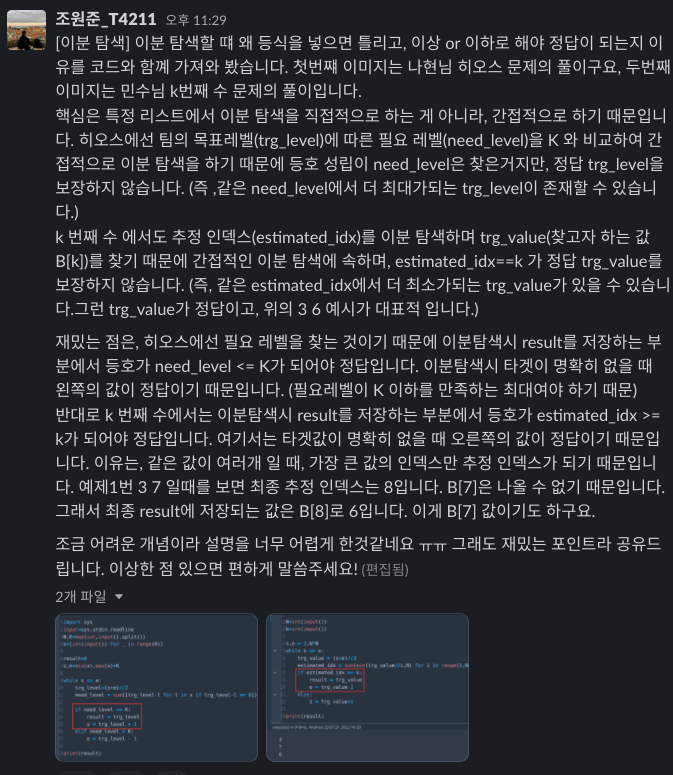
3) 면접 질문 스터디
이번 주 면접 질문 스터디의 주제는 Collaborative Filtering(협업 필터링)이었습니다. 협업 필터링의 한계로 대표적인 Cold Start(콜드 스타트), 연산량 증가, Long-tail 문제를 다루었습니다. 또 CF 모델을 선택하는 기준인 피드백 데이터 종류(Explicit, Implicit)와 어떤 기준으로 평가하는지(Metrics), Bias 등을 다루었습니다. 그 외에도, Memory based 협업 필터링에서 유사도의 종류(코사인 유사도, 피어슨 상관계수, 조정된 코사인 유사도 등)를 다루었고, Cold Start를 해결하는 3가지 방법 profile을 complete 하거나, Feature mapping을 해주거나, 하이브리드 추천 시스템(상황에 적절한 추천 시스템)을 이용하는 것을 다루었습니다. 제가 준비한 주제는 Latent Factor(잠재 요인)과 Latent Factor Model이 무엇인지를 발표했습니다. 대표적인 Latent Factor Model의 예시로 Matrix Factorization을 다루었고, Latent Factor가 커지면 차원의 저주에 걸리는 이유와 MF에서 정규화를 하는 기하학적인 의미(벡터가 원점으로부터 멀어지지 않게 하여, 오버 피팅을 방지하는 것) 등을 다루었습니다.
4) 한 주 회고

3. 그 외 이벤트들
1) 멘토링
이번 주의 메인 콘텐츠는 책 평점 예측 대회입니다. 멘토링 때도 대회를 협업해서 어떻게 진행할지에 대해 다양한 질문들이 오갔습니다. 대회에서 가설을 세우고 검증하는 사이클부터, Rule-Based 모델은 어떤 식으로 짜는지, 역할은 어떻게 나누는 게 좋을지 등 다양한 질문과 답변을 들으며 인사이트를 키우는 시간을 가졌습니다.
2) 마스터클래스(이현호 카카오 뱅크 데이터 사이언티스트 대회 및 면접 팁)
이번 주에는 대회 관련 강의를 준비해주신 이현호 마스터님의 대회와 면접에 대한 팁을 알려주셨습니다. 대회를 하는 게 실무에 어떻게 도움이 되는지를 잘 설명해주셨습니다. 또한, 면접은 어떻게 준비하는 게 좋은지, 주로 네카라쿠배당토라고 하는 기업에서는 어떤 식으로 면접을 진행하는지 등을 자세히 설명해주셔서 좋았습니다.
3) 오피스아워 (대회 베이스라인 코드 해설)
이번 주 오피스 아워에서는 대회 진행을 위해 주신 베이스라인 코드를 해설해주는 시간을 가졌습니다. 베이스라인으로 제공해주신 모델만 7개로 FM, FFM, NCF, WDN, DCN, CNN_FM, DeepCoNN을 제공해 주셨습니다. 이미 데이터 프리 프로세싱부터 모델을 거쳐 평가하는 파이프라인을 구축해주셔서, 해당 파이프라인을 어떻게 업데이트해야 하는지, 깃을 통해 어떤 식으로 협업할 수 있는지 등을 간략하게 알려주셨습니다.
4. 대회

aistages 플랫폼을 이용한 책 추천 대회가 시작되었습니다. V100 GPU가 있는 서버를 제공해주어 정말 좋았습니다. 서버는 어느정도 모두 세팅이 돼있어서 VS Code만 연결하면 되었습니다. 책 이미지 데이터와 Summary 데이터 유저 데이터, 평가 데이터 등이 주어졌습니다. 다음 주 목요일까지 진행되어 열심히 해보려고 합니다.
Reference)
1. 네이버 부스트 캠프 Ai tech 4기
2. 추천 시스템 분류 체계 : 네이버 부스트 캠프 Ai Tech
3. aistages 이미지: https://www.facebook.com/photo/?fbid=10159718611654521&set=pcb.4525941444155648
'Data Science & Analysis > 부스트캠프 Ai tech 4기' 카테고리의 다른 글
| [부스트캠프 AI tech 4기] week 8 회고 📝 - AI 서비스 기초 (0) | 2022.11.20 |
|---|---|
| [부스트캠프 AI tech 4기] week 7 회고 📝 - 책 평점 예측 대회 (0) | 2022.11.06 |
| [부스트캠프 AI tech 4기] week 5 회고 📝 - 추천 시스템 심화 & 데이터 시각화(6~7) (0) | 2022.10.22 |
| [부스트캠프 AI tech 4기] week 4 회고 📝 - 추천 시스템과 데이터 시각화(4~5) (0) | 2022.10.19 |
| [부스트캠프 AI tech 4기] week 3 회고 📝 - DL Basic 과 데이터 시각화(1~3) (0) | 2022.10.10 |