
pydataset은 python에서 빠르게 다양한 종류의 dataset에 접근해서 dataframe을 불러오는 라이브러리입니다.
현재 기준 757개의 데이터셋이 존재합니다.
python으로 dataframe을 다룰 땐 주로 주피터 노트북에서 pandas라는 라이브러리를 사용하게 됩니다.
dataframe을 불러오기만 할 때는 pandas가 필요 없으니 실제 사용 예시들과 함께 pydataset에 대해 알아보겠습니다.
깃허브 코드: https://github.com/netsus/pandas_practice/blob/master/pydataset_practice.ipynb
1. 설치 방법
!pip install pydataset주피터 노트북에서도 앞에 !를 사용함으로써 pip를 통해 툴 설치가 가능합니다.

2. 데이터 종류 보는 법
1) 라이브러리 불러오기
설치가 끝나면 아래 명령어를 통해 pydataset 라이브러리를 불러옵니다.
from pydataset import data* 출력

2) data()
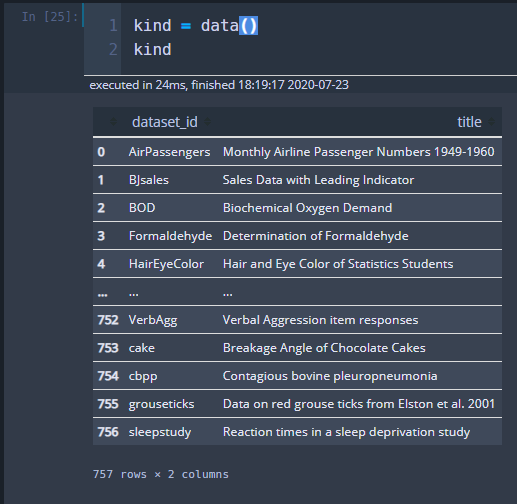
불러온 라이브러리로부터 아래의 사진처럼 data()를 실행하면 dataset에 대한 정보가 담긴 dataframe이 kind에 저장됩니다.
맨 아래 행(row) 개수를 보면 757개의 dataset이 있음을 알 수 있습니다.
* 출력
3. 데이터셋 불러오기
dataset을 불러올 때는 아래의 명령어를 이용하여 불러올 수 있습니다.
df = data('데이터셋 이름')또한 아래의 명령어를 이용해 dataset의 정보를 출력하여 볼 수 있습니다.
df = data('데이터셋 이름', show_doc=True)
4. 예시
1) iris(붓꽃) 데이터셋
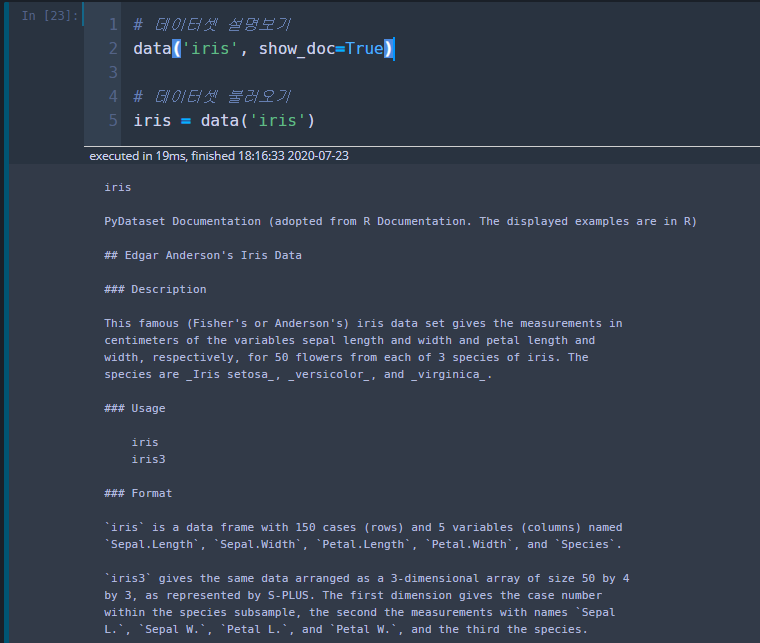
# 데이터셋 설명보기
data('iris', show_doc=True)
# 데이터셋 불러오기
iris = data('iris')dataframe을 다룰 때나, 머신러닝에 입문할 때 주로 쓰는 데이터셋인 iris 데이터셋을 설명과 함께 불러와 보겠습니다.
* 출력
iris를 출력해보면 다음과 같이 나옵니다.
* 출력

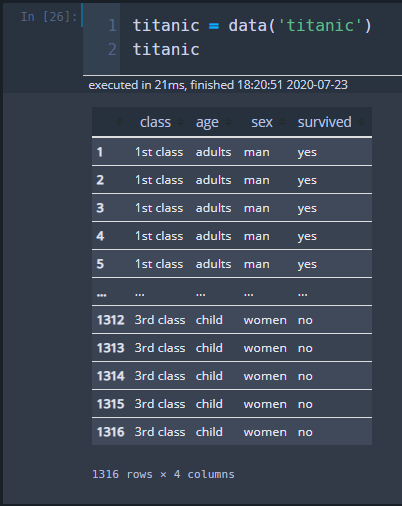
2) titanic 데이터셋
titanic = data('titanic')
titanic머신러닝 competition 사이트로 유명한 캐글(https://www.kaggle.com/)에 입문할 때 주로 Titanic 데이터셋으로 입문합니다.
해당 데이터셋도 pydataset에 있으니 한번 설명과 함께 불러와 보겠습니다.
* 출력
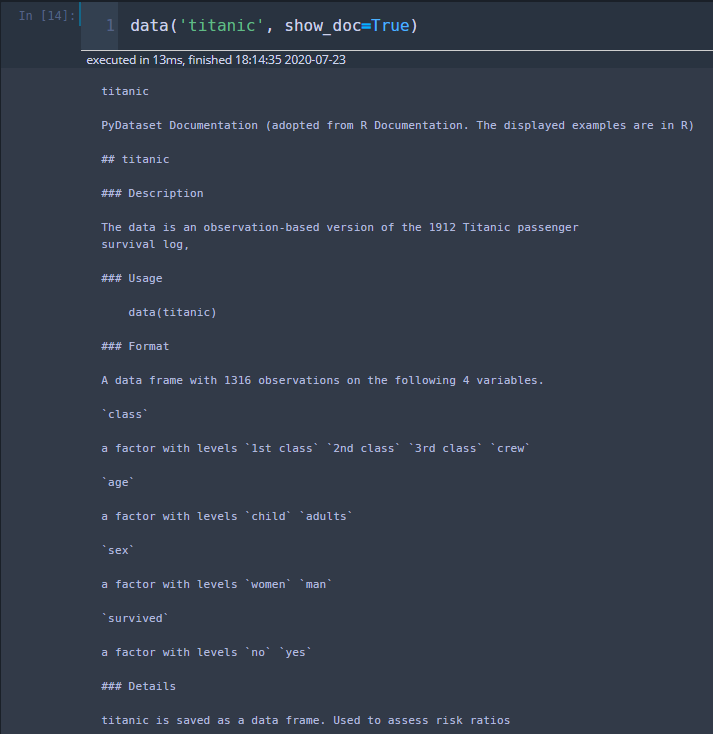
data('titanic', show_doc=True)titanic 데이터 셋의 설명을 보겠습니다.
* 출력
앞으로 pydataset을 이용해서 데이터 프레임을 불러와서 pandas를 통해 데이터를 정제하고 시각화하는 다양한 방법에 대해 알아볼 것입니다.
다음에 더 좋은 글로 찾아오겠습니다.
읽어주셔서 감사합니다.
'Data Science & Analysis > Pandas' 카테고리의 다른 글
| [Pandas] 다중 인덱스 엑셀 읽기 및 처리 (Multi Index, Multi Column) (0) | 2020.09.15 |
|---|---|
| [Pandas] 리스트(list) 순서로 데이터프레임 정렬 (0) | 2020.09.14 |
| [Pandas] Dataframe 비교 - 부분비교와 전체비교 (3) | 2020.08.13 |
| [Pandas] str.extract, str.contains 정규표현식 사용 (0) | 2020.08.06 |
| [Pandas] 유용한 pandas 기능 4 가지 (컬럼 순서 변경, insert, loc, Groupby) (2) | 2020.07.30 |