
* 전체 코드
import pandas as pd
from pydataset import data
df = data('Titanic') ### 테스트 데이터셋 불러오기
### 비교 연산
cond_adult = df.Age=='Adult' # == 연산
df[cond_adult] # True인 값들만 출력
cond_freq_under4 = df.Freq<4 # < 연산
df[cond_freq_under4] # True인 값들만 출력
cond_isin_crew_1st = df.Class.isin(['Crew','1st']) ## isin 연산
df[cond_isin_crew_1st] # True인 값들만 출력
df[~df.Class.isin(['Crew','1st'])] # ~(not 연산)
### 여려 조건 합치기
df[(cond_adult) & (cond_freq_under4)] # &(and)
df[cond_adult | cond_freq_under4] # |(or)
df[(cond_adult) & ~(cond_freq_under4)] # ~(not)
#### 컬럼 지정해서 바꾸기
df.loc[(cond_adult) & (cond_freq_under4),"Class"] = "해적"
#### 행 전체 바꾸기
df.loc[(cond_adult) & (cond_freq_under4)] = ["해적왕", "여자", "GodMother", "Yes", 100]
1. 배경
판다스의 DataFrame을 사용하다 보면, 조건에 따라 행들을 선택하고 싶은 경우가 굉장히 많습니다. SQL로 따지면, Select From Where 절을 사용하는 느낌입니다. 판다스에선 조건에 따라 행들을 선택해서 바로 데이터 프레임으로 볼 수 있습니다. 또한, 조건에 따라 선택된 행들의 값을 바로 변경할 수 도 있습니다. 이번 시간엔 그 방법들을 예시와 함께 자세히 알아보겠습니다.
2. 조건에 따른 행 선택 (Select Row)
1) 테스트 데이터 불러오기
import pandas as pd
from pydataset import data
df = data('Titanic')
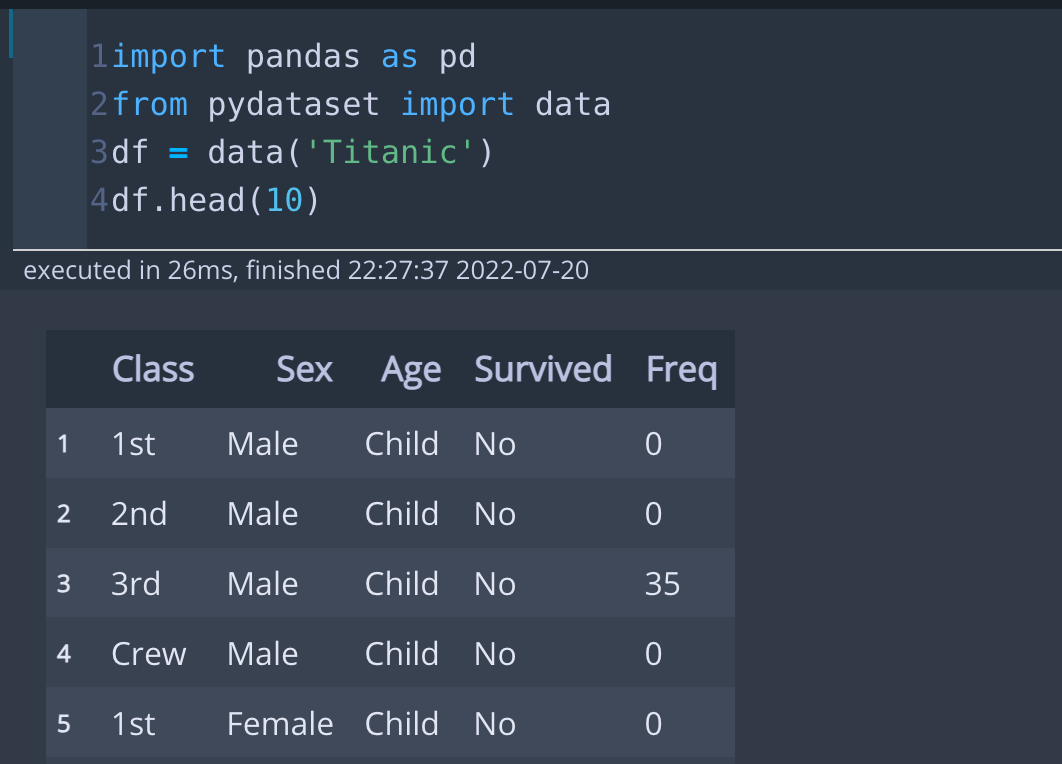
df.head(10)* 코드 설명
pandas라이브러리와 pydataset의 data 모듈을 import 합니다. 'Titanic' 데이터셋을 불러오고 출력합니다.
* 출력
* 각 칼럼(열) 별 값의 종류 확인
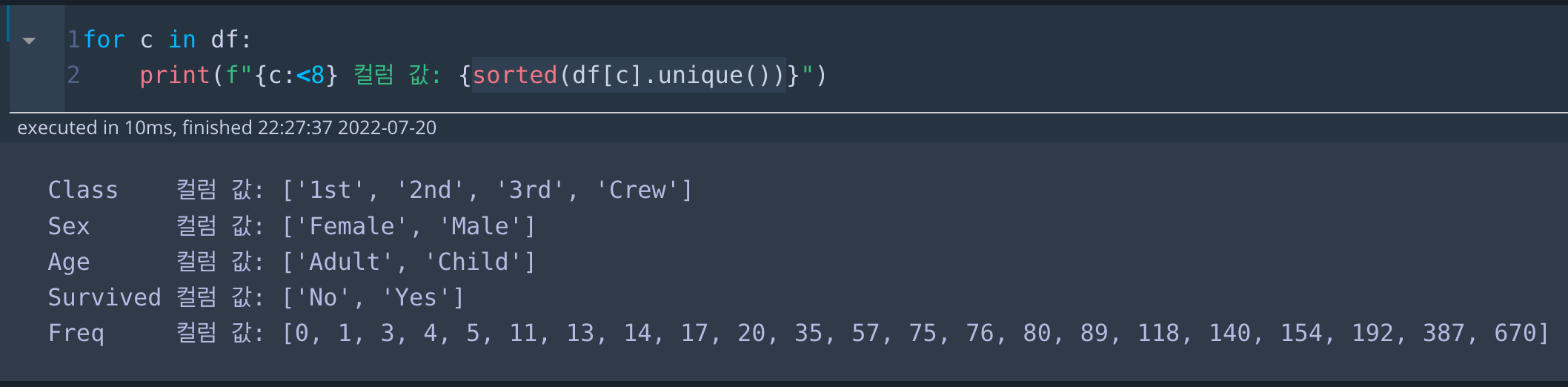
for c in df:
print(f"{c:<8} 컬럼 값: {sorted(df[c].unique())}"* 코드 설명
df를 반복하면 각 칼럼(열)의 이름이 c로 반복됩니다. f-string을 이용해 칼럼이름(c)를 8 단어에 걸쳐(왼쪽 정렬)하고, 컬럼 값을 출력합니다. 칼럼 값은 sorted(df[c].unique()) 코드를 사용했는데, 해당 칼럼의 값의 종류(유니크한 값들)를 정렬(sorted)해서 리스트로 출력하겠다는 뜻입니다. (f-string 정렬 관련 포스팅: [Python] f-string 포맷팅2 (2,8,16 진수, 1000단위 쉼표, 정렬, 문자채우기))
* 출력
2) 비교 연산
| 비교 연산 | 설명 |
| == | 값이 같은 경우 |
| != | 값이 다른 경우 |
| <, <= | 값이 작은 경우, 작거나 같은 경우 |
| >, >= | 값이 큰 경우, 크거나 같은 경우 |
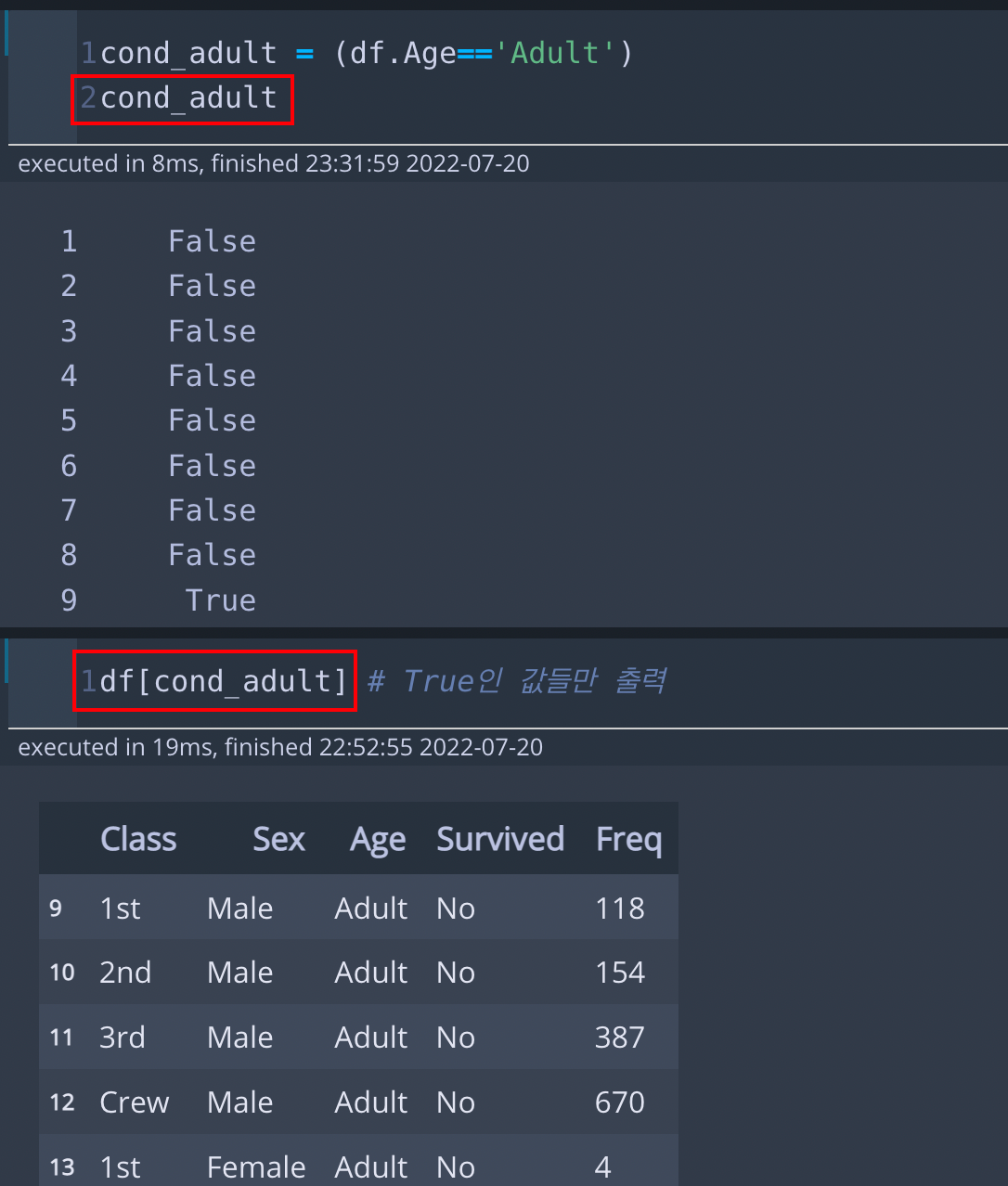
cond_adult = (df.Age=='Adult')
cond_adult # 조건에 따른 True, False 값
df[cond_adult] # True인 값들만 출력* 코드 설명
df에서 Age가 'Adult'인 경우를 구해봅니다. cond_adult에는 시리즈 형태로, 각 Row별로 Adult이면 True, Adult가 아니면 False형태로 값들이 들어있습니다. 이것을 df[cond_adult]로 넣어주면 True인 값들에 해당하는 행들만 데이터 프레임으로 출력해줍니다.
* 출력
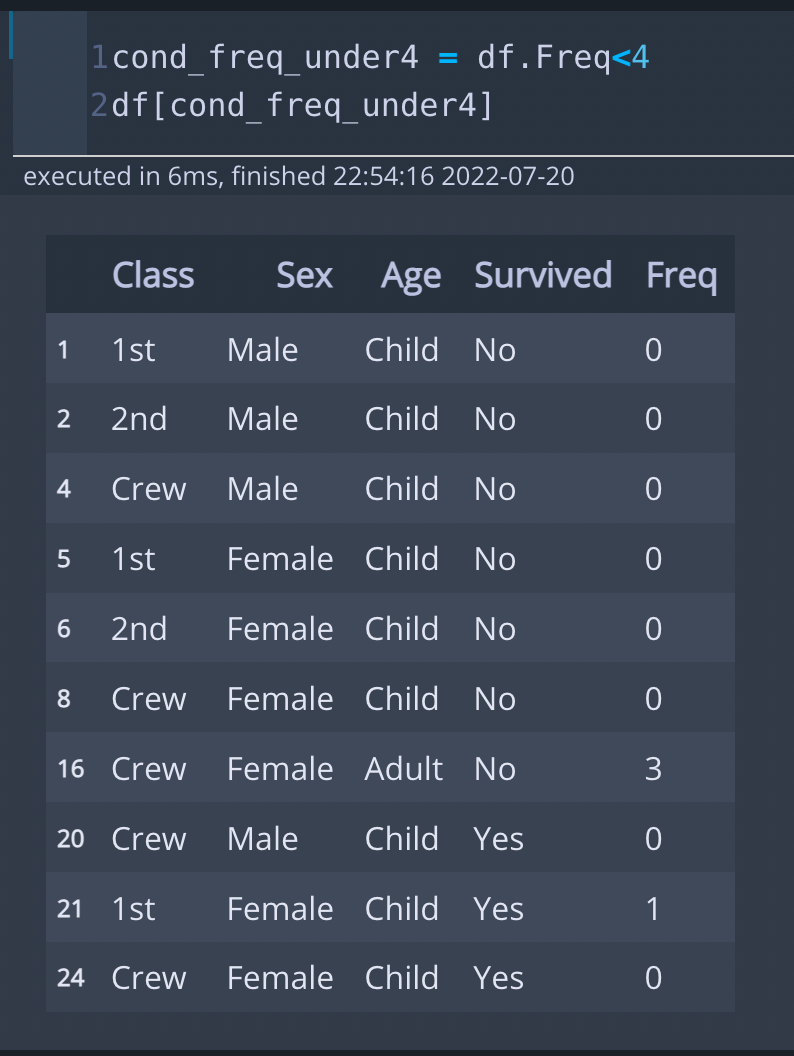
cond_freq_under4 = df.Freq<4 # Freq이 4 미만인 경우
df[cond_freq_under4]* 코드 설명
df.Freq<4은 Freq칼럼의 값이 4 미만인 경우에 대한 시리즈 값입니다. 이를 cond_freq_under4에 저장합니다. 여기서 cond란 condition(조건)의 줄임말입니다. 그리고 df[cond_freq_under4]를 통해 Freq이 4 미만인 경우를 데이터 프레임으로 출력합니다.
* 출력
3) isin 연산
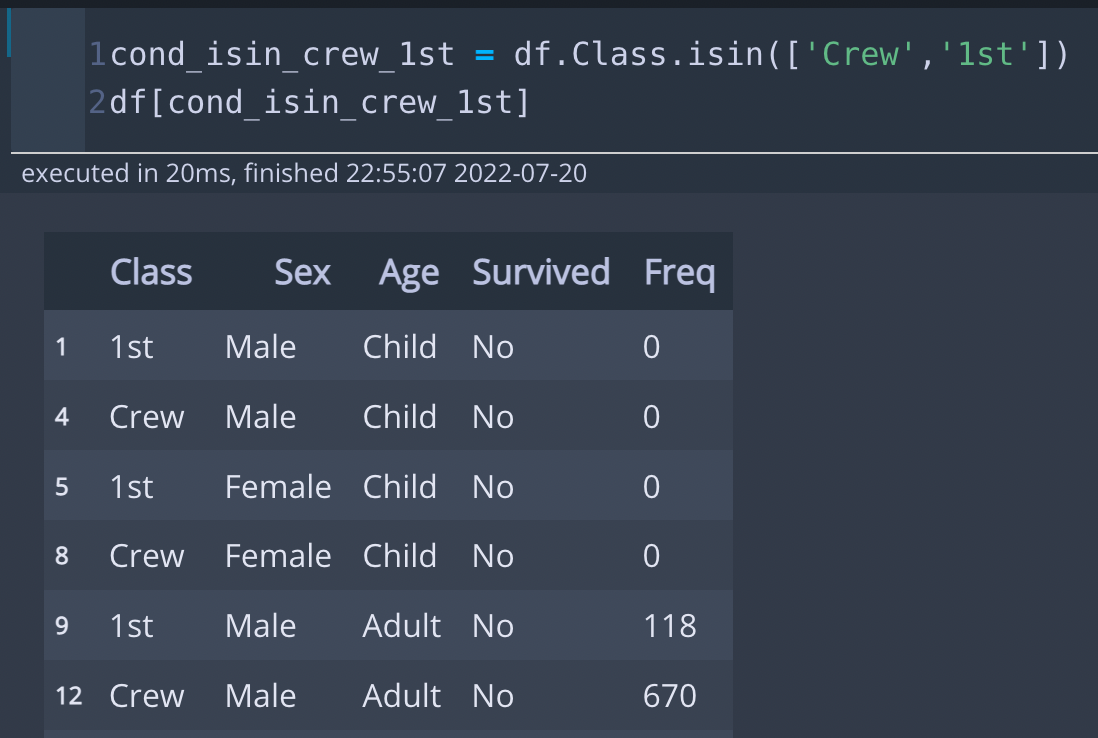
cond_isin_crew_1st = df.Class.isin(['Crew','1st'])
df[cond_isin_crew_1st]* 코드 설명
isin연산은 df.컬럼.isin([리스트]) 형태로 사용합니다. 해당 칼럼에 대해, 리스트에 포함된 값들을 True로 반환합니다. df.Class.isin(['Crew', '1st']) 는 Class 칼럼에 'Crew' 나 '1st'가 포함되어 있는 경우 모두를 의미합니다.
* 출력
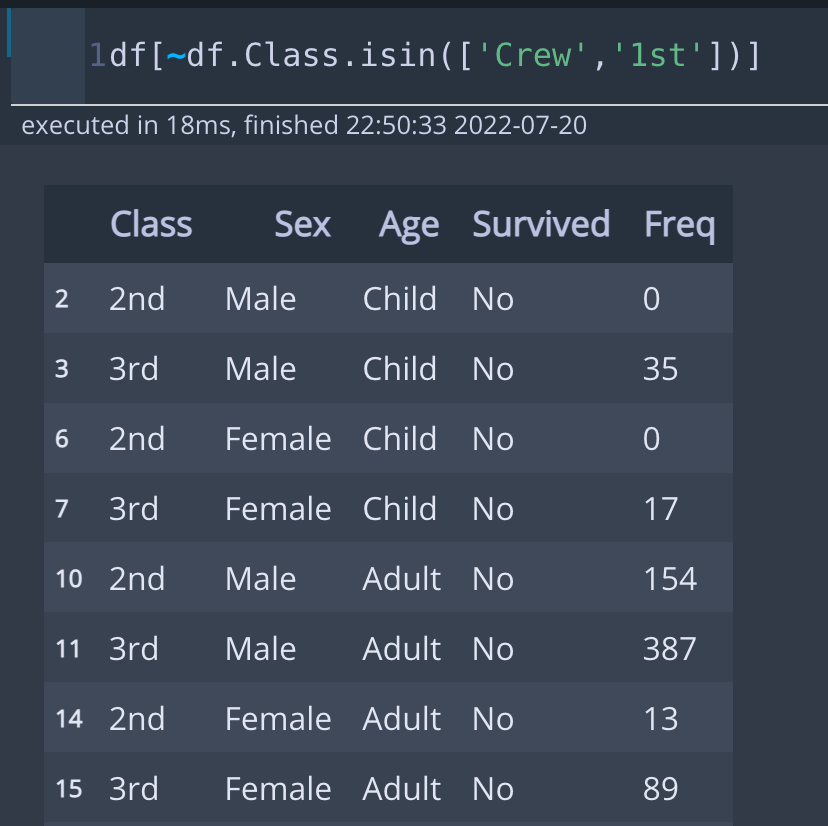
4) not 연산
df[~df.Class.isin(['Crew','1st'])]* 코드 설명
not 연산은 특정 조건(condition) 앞에 물결표('~')를 붙이면 됩니다. 위 예시를 보면, Class가 Crew나 1st인 조건 앞에 "~"를 붙임으로써, Crew나 1st가 아닌 경우로 조건이 바뀌었습니다.
* 출력
5) 여러 조건식 합치기
| 조건간 연산자 | 설명 |
| & | and를 의미. |
| | | or을 의미. |
### 여려 조건 합치기
df[(cond_adult) & (cond_freq_under4)] # &(and)
df[cond_adult | cond_freq_under4] # |(or)
df[(cond_adult) & ~(cond_freq_under4)] # ~(not)* 코드 설명
&는 조건 간 and 연산을 하며, |는 조건 간 or 연산을 합니다. ~(not 연산)과 함께 쓸 수도 있습니다. 위 3가지 예시를 보겠습니다.
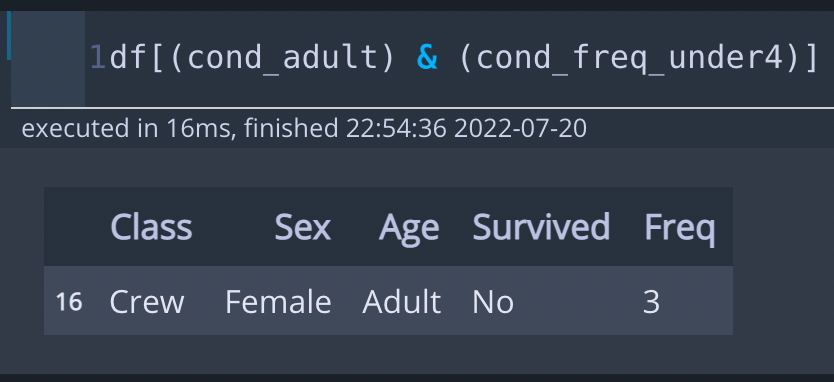
- df[(cond_adult) & (cond_freq_under4)] : 위에서 정의한 Age가 Adult인 경우 그리고, Freq이 4 미만인 경우를 의미합니다. 즉, Age가 Adult 이면서, Freq이 4 미만인 경우가 출력됩니다.
* 출력 1
- df[cond_adult | cond_freq_under4] : Age가 Adult 이거나, Freq이 4 미만인 경우입니다. 두 경우중 하나라도 참이면 출력됩니다.
* 출력 2

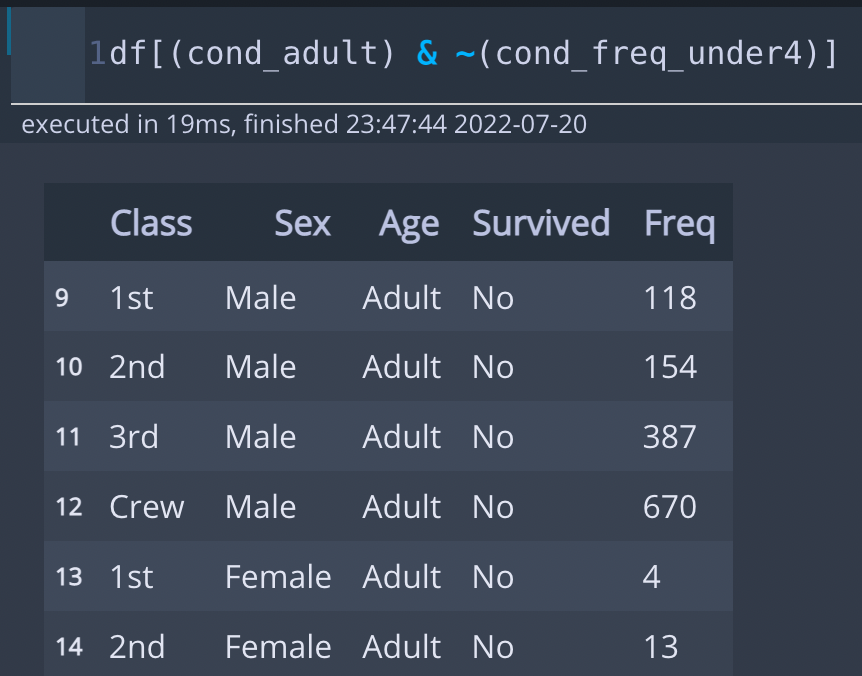
- df[(cond_adult) & ~(cond_freq_under4)] : Age가 Adult인 경우와 Freq이 4 미만이 아니고, 4 이상인 경우를 의미합니다. 즉, Age가 Adult이고, Freq이 4 이상을 동시에 만족하는 경우 출력됩니다.
* 출력 3
3. 선택한 값 바꾸기 (Chage Row)
위에서는 조건을 통해 행을 선택하는 방법을 알아보았습니다. 선택한 행의 값을 바꾸는 방법을 알아보겠습니다.
1) 칼럼 지정해서 변경
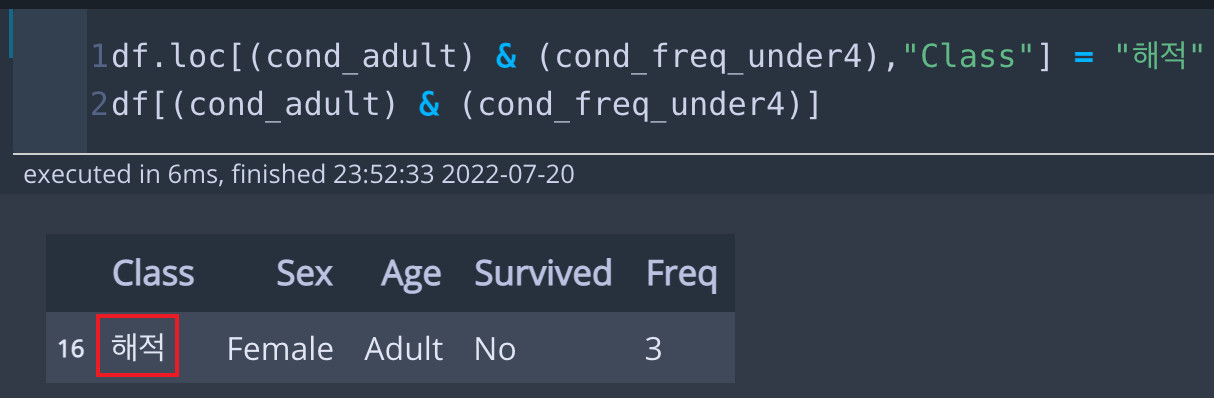
df.loc[(cond_adult) & (cond_freq_under4),"Class"] = "해적"
df[(cond_adult) & (cond_freq_under4)]* 코드 설명
조건으로 선택된 행의 값을 바꾸는 방법은 df.loc[조건,"컬럼이름"]= 바꿀 값입니다. 위 예시를 보면, df.loc[(cond_adult) & (cond_freq_under4),"Class"] = "해적"으로, Age가 Adult이고, Freq이 4 미만인 경우 "Class"칼럼의 값을 "해적"으로 바꾸겠다는 의미입니다. 값을 바꾸고, 잘 변경되었는지 출력해보겠습니다.
* 출력
2) 행 전체 변경
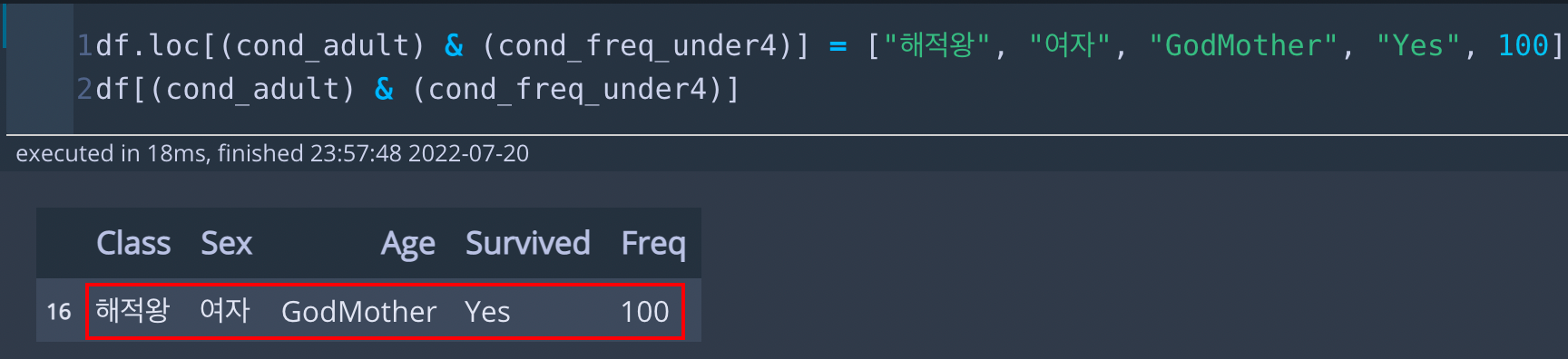
df.loc[(cond_adult) & (cond_freq_under4)] = ["해적왕", "여자", "90", "Yes", 100]
df[(cond_adult) & (cond_freq_under4)]* 코드 설명
행 전체를 바꾸는 방법은 f.loc[조건]= [행 바꿀 값 리스트]입니다. 이때, [행 바꿀 값 리스트]의 요소 개수가 df의 칼럼 개수와 동일하고, 데이터 타입도 일치해야 합니다. 위 코드에서 df.loc[(cond_adult) & (cond_freq_under4)] = ["해적왕", "여자", "90", "Yes", 100] 부분을 보겠습니다. df의 칼럼이 ['Class', 'Sex', 'Age', 'Survived', 'Freq'] 이기 때문에 각각에 맞게 ["해적왕", "여자", "90", "Yes", 100]으로 [문자열, 문자열, 문자열, 숫자형]으로 기존 데이터 타입에 맞게 주었습니다. 그러면 조건에 만족하는 행들이 모두 바뀌게 됩니다.
* 출력
4. 결론
판다스의 데이터 프레임에서 조건에 따라 행을 선택하고, 조건들을 &(and)나 |(or)로 합쳐보기도 하고, 선택된 행의 값을 바꿔보기도 했습니다. 이 연산들은 실제로 데이터 프레임을 다루다 보면 정말 많이 쓰입니다. 캐글 컴페티션 등의 노트북을 보면, 조건들을 변수에 넣고 이리저리 합쳐서 쓰는 경우를 많이 볼 수 있습니다. 위처럼 cond_로 시작하여 많이 사용합니다.
읽어주셔서 감사합니다.
다음에 더 유익하고 재미있는 글로 찾아오겠습니다.
* 위의 실습 코드 깃허브를 공유드립니다. (주피터 노트북)
https://github.com/netsus/pandas_practice/blob/master/Pandas_select_row_with_condition.ipynb
GitHub - netsus/pandas_practice: Pandas examples in practice.
Pandas examples in practice. Contribute to netsus/pandas_practice development by creating an account on GitHub.
github.com
'Data Science & Analysis > Pandas' 카테고리의 다른 글
| [Pandas] Dataframe의 행을 반복하는 방법 (iterrows, itertuples, index, loc, iloc) (0) | 2022.07.13 |
|---|---|
| [Pandas] JSON 읽고 DataFrame으로 상호 변환하기 (1) | 2022.03.30 |
| [Pandas] 다중 인덱스 엑셀 읽기 및 처리 (Multi Index, Multi Column) (0) | 2020.09.15 |
| [Pandas] 리스트(list) 순서로 데이터프레임 정렬 (0) | 2020.09.14 |
| [Pandas] Dataframe 비교 - 부분비교와 전체비교 (3) | 2020.08.13 |