1. 배경
파이썬에서 텍스트 파일을 읽고, 쓰는 것만으로 충분치 않을 때가 있습니다. 파이썬에서 pickle을 이용하면, 변수를 그대로 저장했다가 불러올 수 있습니다. 예를 들어, python 자체 자료형인 리스트, 딕셔너리 등뿐만 아니라, pandas의 데이터 프레임, 심지어 함수와 클래스까지 파일로 저장하고 불러올 수 있습니다. 그 방법을 알아보겠습니다.
2. 기초 사용법

# python 변수(객체)를 pickle 파일로 저장
with open([파일], 'wb') as f:
pickle.dump([변수], f)
# pickle 파일 불러오기
with open([파일], 'rb') as f:
var = pickle.load(f)pickle.dump를 이용해 [변수]를 [파일]에 저장합니다. 이때, open 함수에서 [파일]에 'wb'로 저장합니다. 'wb'란 write binary라는 뜻으로, 이진수로 쓰겠다는 의미입니다. 이렇게 쓰는 이유는, pickle 파일이 이진수로 이루어진 파일이기 때문입니다. 즉, pickle파일은 python에 특화된 binary 파일입니다.
반대로, pickle 파일을 변수로 읽어올 때는 open 함수에서 [파일]을 'rb'로 불러옵니다. 'rb'란 read binary라는 뜻으로, 이진수 파일을 읽어오겠다는 뜻입니다. 그리고 pickle.load(f)를 통해 해당 파일(f)을 파이썬 객체(변수)로 저장할 수 있습니다.
3. 예시
Python의 리스트부터 데이터 프레임, numpy 라이브러리의 함수, 클래스를 각각 pickle로 저장하고 불러오는 실습을 해보겠습니다.
1) Python 리스트 다루기
① 전체 코드
import pickle
li=[0,1,2,3,4,5]
## pickle은 python에 특화된 binary 파일이다.
with open("list.pickle","wb") as f:
pickle.dump(li, f) # 위에서 생성한 리스트를 list.pickle로 저장
with open("list.pickle","rb") as fi:
test = pickle.load(fi) # list.pickle 읽어서 출력 -> list 잘 불러와졌다.
# pickle로 불러온 test의 type과 값 출력
print(type(test))
print(test)
② 설명
import pickle
li=[0,1,2,3,4,5]먼저 pickle을 import 하고, li라는 변수에 Python의 리스트를 할당합니다.
## pickle은 python에 특화된 binary 파일이다.
with open("list.pickle","wb") as f:
pickle.dump(li, f) # 위에서 생성한 리스트를 list.pickle로 저장
with open("list.pickle","rb") as fi:
test = pickle.load(fi) # list.pickle 읽어서 출력 -> list 잘 불러와졌다.이제 "wb"를 이용해 "list.pickle" 파일에 쓴다는 open 함수의 결과를 f에 할당합니다. pickle.dump(li, f)를 통해 li(파이썬 리스트)를 f에 저장합니다.
그 후, "rb"를 이용해 "list.pickle" 파일을 읽어온 open 함수의 결과를 fi에 할당하고, pickle.load(fi)로 fi를 읽어서 test 변수에 저장합니다.
# pickle로 불러온 test의 type과 값 출력
print(type(test))
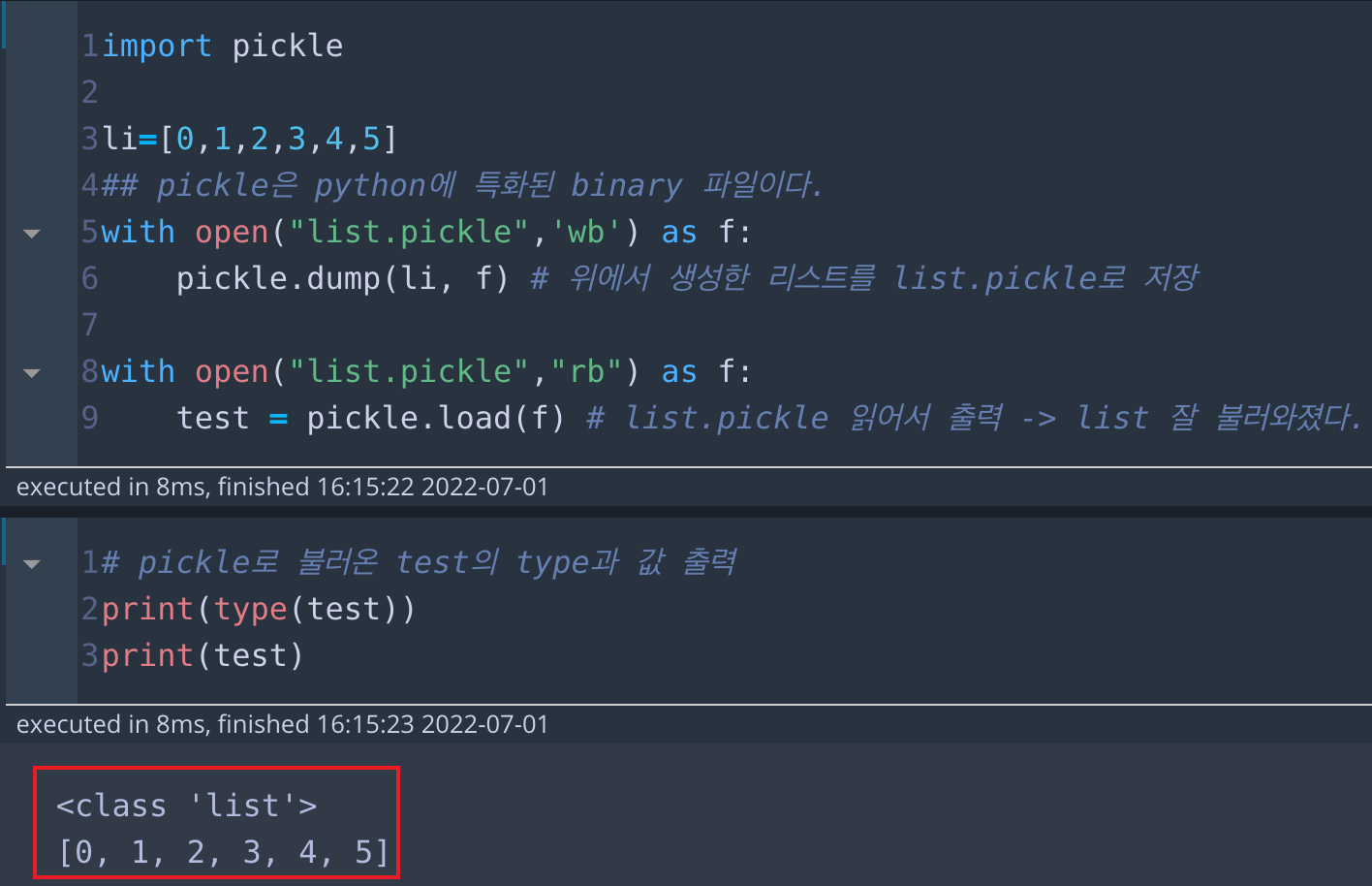
print(test)위에서 저장한 test변수의 타입과 값을 출력하면, 아래 그림처럼 list 타입과 위에서 li로 생성한 값이 그대로 저장되어 있는 것을 볼 수 있습니다.
* 출력
2) Pandas 데이터 프레임 다루기
① 전체 코드
import pickle
import pandas as pd
df = pd.DataFrame({'A':[0,1],'B':[2,3]})
## pickle은 python에 특화된 binary 파일이다.
with open("df.pickle","wb") as f:
pickle.dump(df, f) # 위에서 생성한 데이터 프레임을 df.pickle로 저장
with open("df.pickle","rb") as fi:
test = pickle.load(fi) # df.pickle 읽기
# 출력해보면 pandas의 데이터프레임이 그대로 잘 출력됨.
print(type(test))
test
② 설명
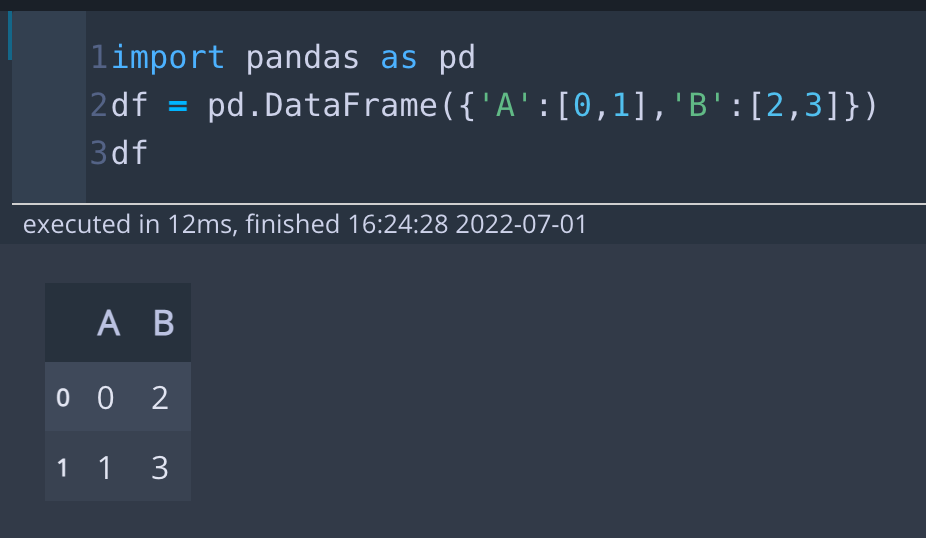
import pandas as pd
df = pd.DataFrame({'A':[0,1],'B':[2,3]})
df먼저 pandas 라이브러리를 import 합니다. 그 후, 간단한 데이터 프레임을 만들었습니다.
* 출력
## pickle은 python에 특화된 binary 파일이다.
with open("df.pickle","wb") as f:
pickle.dump(df, f) # 위에서 생성한 데이터 프레임을 df.pickle로 저장
with open("df.pickle","rb") as fi:
test = pickle.load(fi) # df.pickle 읽어서 출력해보기 -> 데이터프레임그대로 잘 불러와졌다.
print(type(test))
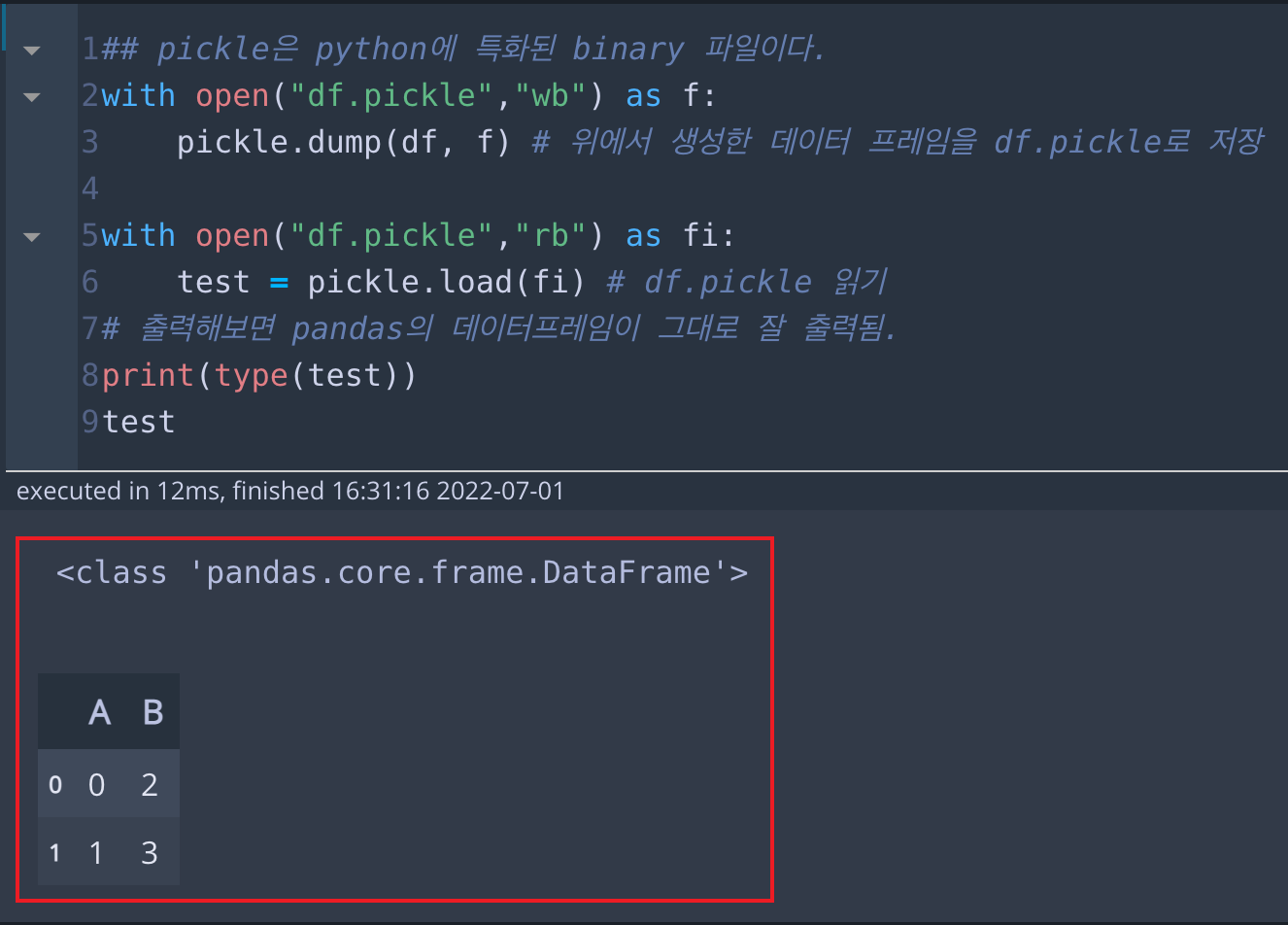
test위에서 생성한 데이터 프레임(df)을 똑같은 방법으로 pickle로 저장하고, test 변수에 불러온 뒤, 출력해보겠습니다. type은 pandas의 Dataframe으로 출력되고, 데이터 프레임 내용 역시 잘 출력되는 것을 알 수 있습니다.
(pickle은 클래스 자체도 불러오는 게 가능하기 때문에, pickle 파일을 불러오는 코드에 pandas가 import 되지 않아도 데이터 프레임[클래스]이 불러와집니다.)
* 출력
3) Python 함수 다루기
① 전체 코드
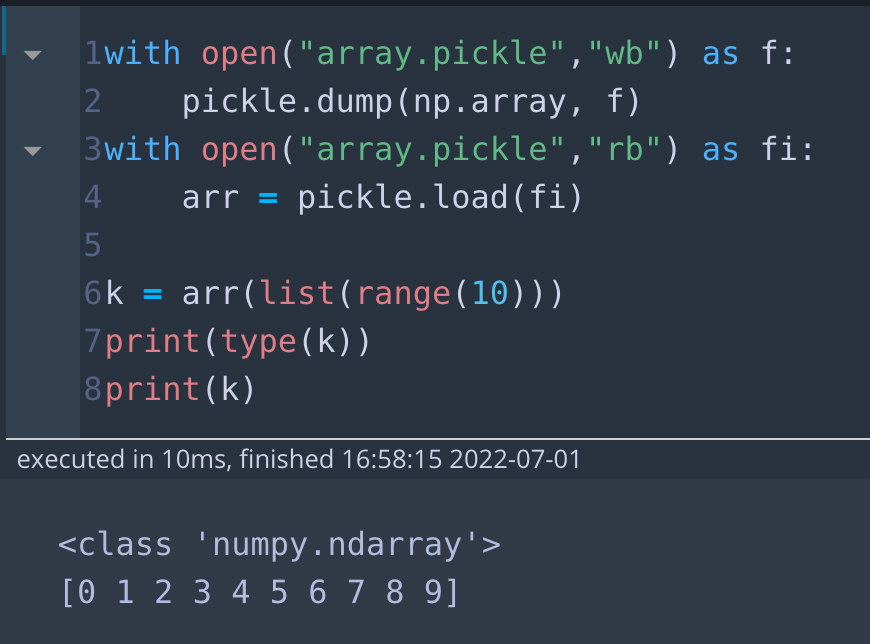
import numpy as np
print(np.array)
with open("array.pickle","wb") as f:
pickle.dump(np.array, f)
with open("array.pickle","rb") as fi:
arr = pickle.load(fi)
k = arr(list(range(10)))
print(type(k))
print(k)
② 설명
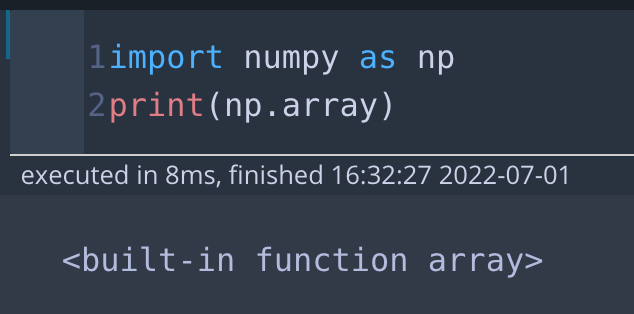
numpy에는 리스트를 ndarray로 변환해주는 built-in funciton인 array함수가 있습니다.
import numpy as np
print(np.array)* 출력
with open("array.pickle","wb") as f:
pickle.dump(np.array, f)
with open("array.pickle","rb") as fi:
arr = pickle.load(fi)
k = arr(list(range(10)))
print(type(k))
print(k)np.array 함수를 "array.pickle"에 저장하고, 변수 arr에 불러왔습니다. 이제 arr은 np.array함수입니다. 위 코드에서 list(range(10))은 0부터 9까지의 숫자 리스트입니다. 이를 arr함수를 적용해 k에 넣고, 그 타입과 값을 출력해보겠습니다. 아래 결과를 보면 타입은 numpy.ndarray이고, 배열도 잘 출력된 것을 볼 수 있습니다.
* 출력
4) Python 클래스 다루기
① 전체 코드
# 클래스 내부에 multiplier 값을 저장
# 이후에 multiply 메소드에 들어오는 값을 multiplier와 곱해서 반환
class Multiply(object):
def __init__(self, multiplier):
self.multiplier = multiplier
def multiply(self, num):
return num * self.multiplier
mply = Multiply(3) # multiplier를 3으로 지정
print(mply.multiply(3)) # multiplier * 3 반환 => 9
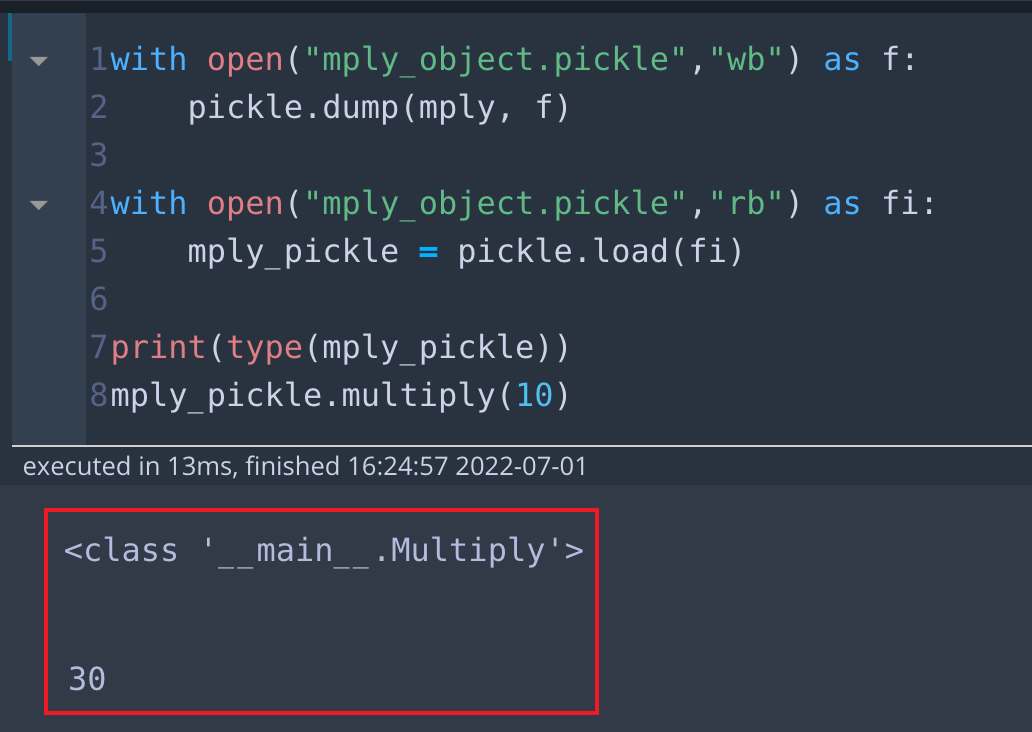
with open("mply_object.pickle","wb") as f:
pickle.dump(mply, f)
with open("mply_object.pickle","rb") as fi:
mply_pickle = pickle.load(fi)
print(type(mply_pickle))
mply_pickle.multiply(10)
② 설명
# 클래스 내부에 multiplier 값을 저장
# 이후에 multiply 메소드에 들어오는 값을 multiplier와 곱해서 반환
class Multiply(object):
def __init__(self, multiplier):
self.multiplier = multiplier
def multiply(self, num):
return num * self.multiplier
mply = Multiply(3) # multiplier를 3으로 지정
mply.multiply(3) # multiplier * 3 반환 => 9위 Multiply 클래스는 처음에 클래스를 만들 때, multiplier값을 넣어주며 만듭니다. 이후에 multiply 메서드를 실행하면, 넣어주는 값과 클래스를 만들 때 넣어준 multiplier를 곱해줍니다. 클래스 내부에 저장된 변수(self.multiplier)까지 pickle에 저장되는지 확인을 위해 multiplier를 만들었습니다. 위의 예시는, 초기에 multiplier로 3을 넣어주고, 이후에 multiply 메서드에 3을 넣어줘 3*3을 출력합니다.
* 출력

with open("mply_object.pickle","wb") as f:
pickle.dump(mply, f)
with open("mply_object.pickle","rb") as fi:
mply_pickle = pickle.load(fi)
print(type(mply_pickle))
mply_pickle.multiply(10)위에서 self.multiplier를 3으로 생성한 mply라는 클래스를 pickle에 저장하고 불러왔습니다. 그리고 type과 multiply 메서드에 10을 넣은 값을 출력해보겠습니다. 아래 결과를 보면, 타입은 class Multiply로 잘 불러와졌고, 10을 넣었을 때 30을 반환함을 통해, 클래스 내부의 변수도 잘 불러와졌음을 알 수 있습니다.
* 출력
4. 결론
python 프로젝트를 진행하다 보면 python 코드가 많아져서, 특정 변수를 다른 파이썬 스크립트에 전달하고 싶을 때가 있습니다. 그 변수가 class 기반의 다양한 메서드와 값들을 가졌다면 더더욱 해당 변수를 다른 코드에 전달하기 어렵습니다. 이럴 때, pickle을 쓰면 스크립트와 스크립트 간의 소통을 매우 깊이 있게 할 수 있다는 점이 매력적입니다.
읽어주셔서 감사합니다.
다음에 더 유익하고 재미있는 글로 찾아오겠습니다.
위의 예제 코드 깃허브를 공유드립니다.
https://github.com/netsus/python_practice/blob/master/Pickle_list_dataframe_func_class.ipynb
GitHub - netsus/python_practice: basic python course
basic python course. Contribute to netsus/python_practice development by creating an account on GitHub.
github.com
Reference
1. https://dojang.io/mod/page/view.php?id=2327
'Programming > Python 꿀팁' 카테고리의 다른 글
| [Python] 편리한 꿀팁! f-string으로 변수와 값 쉽게 출력 (= 지시자) (1) | 2022.07.09 |
|---|---|
| [Python] Python 코드 실행시간 측정 4가지 방법 (feat. Jupyter Notebook) (2) | 2022.07.06 |
| [Python] f-string 포맷팅2 (2,8,16 진수, 1000단위 쉼표, 정렬, 문자채우기) (0) | 2022.06.25 |
| [Python] f-string 포맷팅 (소수점, 퍼센트, 부동소수점) (0) | 2022.06.16 |
| [Python] 유용한 새로운 연산자! 바다코끼리 연산자 := (walrus operator) (0) | 2022.04.08 |