
1. 대회 진행 내용
저는 이번 주에 DKT 대회에서 Feature Engineering을 주로 했습니다. Feature Engineering 하면, LGBM으로 성능을 측정하고 MLflow에 실험 기록까지 되도록 Baseline을 만들었고, 계속 실험하고, 데이터를 깊게 보고, 성능이 올라가거나 내려갔으면 데이터로부터 그 원인을 찾는 것에 모든 시간과 노력을 쏟았습니다. 아래는 제가 실험한 내역을 MLflow에 기록한 화면입니다. 제출한 경우 LB(Leader Board) AUC에 그 점수를 적었습니다.

CV Strategy를 짜다가 막힌 부분과, Validation AUC가 Validation Set을 어떻게 설정해도 항상 좋아지는 피처가 있는데, 제출만 하면 성능이 안 좋게 나와 그 원인을 찾는데 꽤 삽질을 했습니다. 해당 피처를 Feature Importance(gain, split)으로 봐도 매우 높게 나와서 많이 헤맸습니다. 그러다 XAI(eXplainable AI)라는 분야를 알게되었고, shap이라는 라이브러리를 발견해서 해당 피처에 대해 모델에 어떤 영향을 미치는지도 시각화해봤습니다. 아래가 그 결과입니다.

데이터를 파다보니 그 원인은 정말 어이없게도, answerCode라는 정답률 기반으로 생성한 피처인데, 최종 테스트 셋은 answerCode가 -1로 되어있습니다. 그러다 보니, 예측하는 데이터셋에서 생성된 피처가 -1 값 때문에 편향이 생겼고, Validation Data에는 효과적이었는데 테스트 셋에는 역효과가 났던 것이었습니다. 뼈아픈 결과였지만, 그 과정에서 Validation Set을 Align 하며 실험하는 방법도 체득했고, Feature Importance를 보는 방법과 eXplainable AI라는 분야를 알게 되었으니 나쁘지만은 않았습니다. 외에도 현재 주어진 Sequence Data를 Memory 기법을 이용해 Tabular Data로 변환하는 다양한 테크닉을 익혀서 좋았습니다. 다음 주 목요일까지 대회이니 남은 시간도 최선을 다해보려고 합니다.
2. 피어 세션
1) 일반
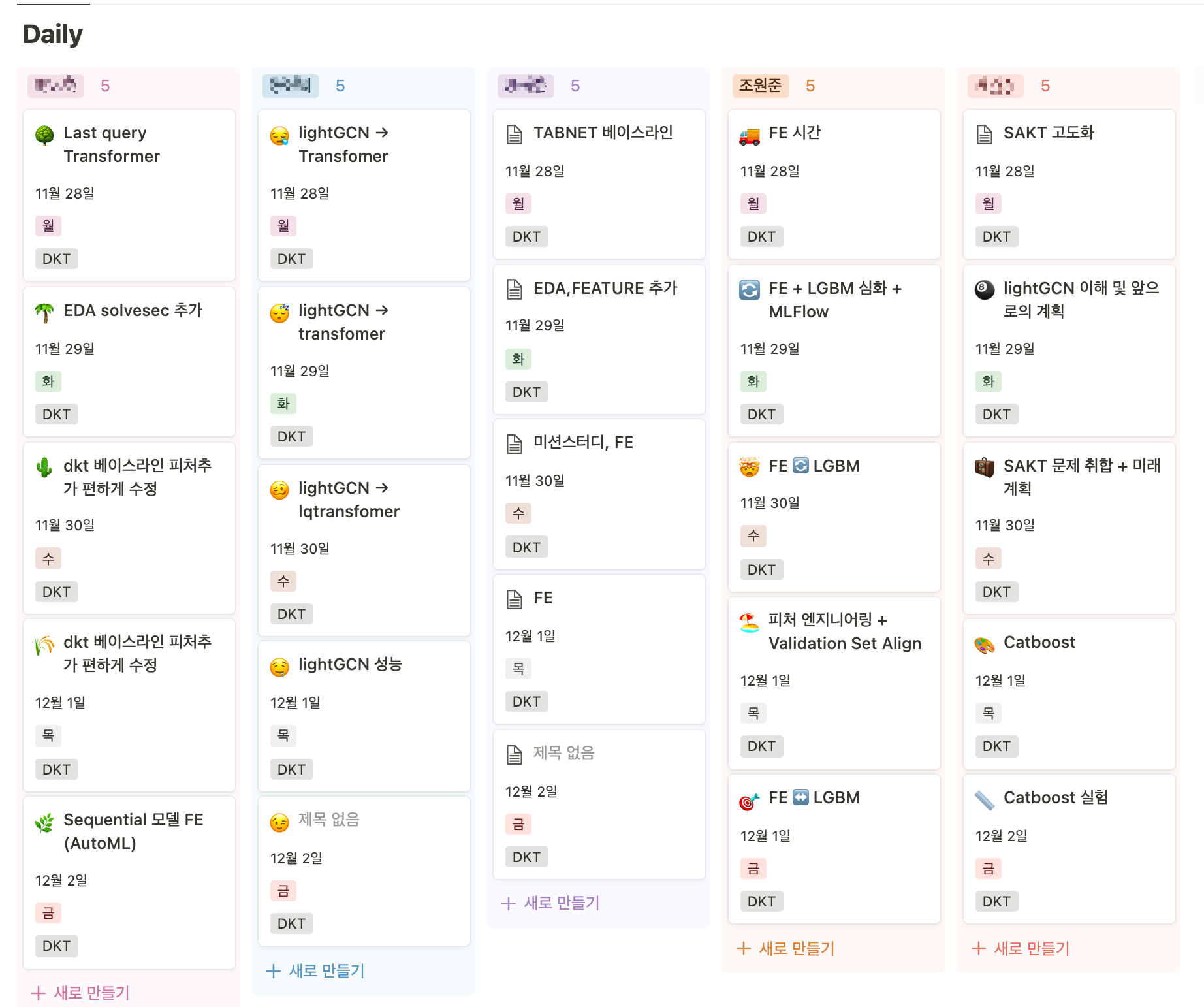
매일 Daily로 진행한 일과 어떤 어려움이 있었고, 어떤 방향으로 극복하려고 했는지 공유 노션에 정리하고, 돌아가며 스크럼을 진행했습니다. 제가 진행한 일들을 설명하고, 어디서 어려움이 있었는지 공유했는데, 혼자라면 절대 못찾았을 문제점들을 팀원들이 발견하고 알려주셔서 정말 고마웠습니다. 저는 주로 Feature Engineering을 진행하고, LGBM으로 성능을 검증하며 데이터를 깊게 파악하는 일을 했습니다. 팀원들이 진행한 일과 어디서 막혔는지에 대해 얘기할 때, 이해가 안 되면 물어보기도 하고, 생각난 인사이트가 있으면 공유를 하면서, 직면한 문제를 함께 풀어가는 느낌을 받아서 정말 좋았습니다.
2) 코딩 테스트 스터디
이번주에는 그리디와 관련된 알고리즘을 풀어와 한 문제씩 발표하고 의견을 나누었습니다. 주로 정렬을 하고, for문을 돌며 최적의 선택을 하는 문제들이 많았습니다. 제가 맡은 문제는 백준 14939의 불 끄기 문제였습니다. 브루트 포스와 그리디가 섞인 신기하고 어려운 문제입니다.

3) 면접 질문 스터디
이번 주 면접 질문 스터디의 주제는 현재 진행하는 DKT 대회와 관련된 모델 이었습니다. 제가 맡은 주제는 Transformer와 LSTM을 합친 모델을 코드 수준에서 연구하여 발표했습니다. data load부터 validation 및 train 과정을 표로 정리하여 발표했습니다.


해당 모델을 wandb에 연결해보기도 했습니다.

외에도, 다른 분들은 SAKT/Saint 모델, LightGCN의 임베딩을 활용한 Last Query Transformer, TabNet, Last Query Transformer를 주제로 발표해주셨습니다.
4) 모델 구현 스터디
모델 구현 스터디 역시 DKT 대회 관련된 모델에 대해 공부하여 발표했습니다. 저는 현재 맡고 있는 부스팅 계열의 LightGBM 모델에 대해 발표했습니다. GBDT(Grandient Boosting Decision Tree)의 메인 아이디어와 한발짝 더 나아가 LGBM의 특별한 방법론인 GOSS(Gradient based One Side Sampling)과 EFB(Exclusive Featrue Bundling)에 대해 발표했습니다. 목차는 아래와 같습니다.

외에도, 다른 분이 LSTM Attention 모델에 대해 기존 Seq2 Seq 모델과 어떻게 다른지 발표해주셨습니다.
5) 한 주 회고

3. 그 외 이벤트들
1) 멘토링
이번주 멘토링에선 DKT 대회를 진행하며 막혔거나, 의문이 드는 부분을 질문하면 멘토님이 답변해주시는 방향으로 진행되었습니다. 제 질문은 Validation Auc가 어떻게 해도 높아져서 성능이 좋아지는데, 제출하면 LB(Leader Board) 점수가 항상 떨어져서 어떤 원인에서 그럴지 여쭤봤습니다. 그 과정에서 데이터의 이상치나 제가 다루던 부스팅 계열 모델이 Sequence Data를 Tabular Data로 변환할 때 시간축을 주는 Lag 기법에 대한 개념을 알려주셨습니다. 결국 나중에 데이터의 이상치를 발견하였습니다. 외에도 부스트 캠프를 하며 모델을 하나만 깊게 파는 것과 여러 모델을 얕게 아는 것 중 어떤 게 좋은지에 대한 질문이 나왔습니다. 결론은 회사마다 쓰는 모델이 다르니, 하나의 모델만 공부하는건 리스크가 있고, 여러 모델을 얕게 아는 것도 메리트가 없으니, 트레이드오프 관계이기 때문에 몇몇 주요 모델을 어느 정도는 구현할 수 있을 정도로 깊게 알아야 한다는 결론이 나왔습니다.
2) 컴퍼니데이
이번 주에는 리빌더AI와 업 스테이지의 회사 소개를 하는 컴퍼니 데이를 진행했습니다. 리빌더AI는 3D 모델을 AR 증강현실에 바로 표현할 수 있고, 현실의 물건을 스캔해서 3D 모델링을 한다는 매우 신박하고 재밌는 일을 했습니다. QR 코드를 찍고, 나오는 웹페이지에서 도넛을 선택한 다음에 맥북의 트랙패드에 도넛을 가져가니 아래 사진처럼 3D 모델이 현실 사진에 그림자와 함께 나와 재밌었습니다.

업스테이지는 각 CV, NLP, RecSYS에서 어떤 일을 하는지, 인턴으로 들어가려면 어떤 역량이 필요한지 등을 팀별로 나와 자세히 설명 주셔서 정말 좋았습니다.
Reference)
1. 네이버 부스트 캠프 Ai tech 4기
'Data Science & Analysis > 부스트캠프 Ai tech 4기' 카테고리의 다른 글
| [부스트캠프 AI tech 4기] week 12 회고 📝 - DKT 대회 종료 (0) | 2022.12.10 |
|---|---|
| [부스트캠프 AI tech 4기] week 10 회고 📝 - DKT 대회 (0) | 2022.11.26 |
| [부스트캠프 AI tech 4기] week 9 회고 📝 - DKT 대회 시작 (0) | 2022.11.20 |
| [부스트캠프 AI tech 4기] week 8 회고 📝 - AI 서비스 기초 (0) | 2022.11.20 |
| [부스트캠프 AI tech 4기] week 7 회고 📝 - 책 평점 예측 대회 (0) | 2022.11.06 |