
1. 강의 내용
1) Deep Learning Basic
1️⃣ 딥러닝의 역사
1강에서는 딥러닝분야에서 중요한 덕목과 Key Components와 역사를 배웠습니다. 딥러닝 분야에서 중요한 덕목은 구현 실력과 수학 스킬, 최신 트렌드의 논문을 읽고 이해하는 능력을 나뉜다고 합니다. 딥러닝의 Key Components는 아래 4가지 입니다.
1. Data: 학습 및 테스트할 데이터
2. Model: 학습할 모델
3. Loss Function: 학습에 사용되는 Loss 함수로, 모델을 어떻게 학습할지에 대한 기준입니다.
4. Algorithm: Loss를 최소화하는 알고리즘 ex) Adam Optimizer
딥러닝의 역사는 2012년 부터 2020년까지 딥러닝 분야에서 굵직한 BreakThrough들을 정리한 것 입니다. 이는 Denny Brits의 Deep Learning's Most Important Ideas라는 논문을 요약한 것 입니다.
[2012] AlexNet : 이미지 분류 대회에서 인공신경망 형태의 딥러닝이 최초로 머신러닝을 이기고 우승한 케이스. 이 때 이후로 이미지넷 분류 대회에서 머신러닝이 딥러닝모델을 이긴적이 없습니다. 즉, 패러다임 시프트가 일어난 사건입니다.
[2013] DQN : 딥마인드가 강화학습(Q-Learning)을 처음 논문으로 낸 것입니다. 이 논문을 보고 구글에 합병되었고, DQN을 기반으로 알파고가 만들어집니다.
[2014] Encoder/Decoder : NMT(기계번역) 분야에서 나온 개념으로 Encoder는 입력으로 들어온 문장을 벡터화하는 것이고, Decoder는 인코딩된 벡터를 기반으로 다른 언어의 문장으로 바꾸는 것입니다. 구글 번역이 갑자기 좋아진 근본 기술이 아닐까 합니다.
[2014] Adam Optimizer : Loss Function을 최소화하는 알고리즘인데 지금까지 많은 논문들에서 General하게 쓰이고 있는 Optimizer 입니다.
[2015] GAN(Generative Adversarial Network) : Generator와 Discriminator가 서로 경쟁하며 학습하는 생성모델로 이미지나 문장을 생성하는 생성모델 분야에 혁신을 가져왔습니다.
[2015] ResNet : 2015년 이미지넷에서 우승한 모델로 이미지를 분류하는 분야에서는 최초로 사람의 능력을 넘어선 모델입니다. 기존 딥러닝 분야에서는 네트워크를 깊게 쌓으면 학습이 안되 성능이 안나오는 근본적인 문제가 있었는데, 이 문제를 해결한 모델입니다.
[2017] Transformer : Transformer는 "Attention Is All You Need"라는 도발적인 제목으로 구글에서 낸 논문에서 소개된 모델입니다. 트랜스포머는 RNN의 구조를 모두 대체했고, Vision 분야에 까지 사용되는 모델입니다.
[2018] BERT: 대규모 학습으로 진행된 모델로, 이 Pretrained Model을 불러와 Fine-Tuning 하는 식의 학습이 성능이 잘 나온다는 패러다임의 변화를 만들어냈습니다.
[2019] GPT-X: OpenAI에서 만든 모델로 BERT의 끝판왕으로 볼 수 있습니다. GPT-3은 1750억개라는 어마어마한 양의 파라미터로 학습된 모델입니다.
[2020] Self Supervised Learning: 학습 데이터가 한정적일 때, 학습 데이터외에 라벨을 모르는 Unsupervised Data도 같이 학습시킨다는 패러다임을 불러왔습니다.
2️⃣ 인공신경망과 MLP(Multi Layer Perceptron)
2강에서는 신경망(Neural Networks)의 정의와 간단한 예시로 MLP를 배웠습니다. 비행기가 처음에는 새의 모양을 모방했지만, 항공역학적으로 학문이 발달하면서 새의 형태와는 거리가 멀어진 것 처럼, 딥러닝의 신경망(Neural Network)도 뉴런의 신경전달을 모방했지만, 수학적으로 선형 변환(행렬곱)과 비선형 변환(nonlinear transformation)을 효과적으로 반복한 네트워크라는 측면에서 이해하는게 좋은 방향으로 보인다고 합니다. 딥러닝의 가장 기초적인 예시로 선형 회귀 y = wx + b에서 w와 b 파라미터를 찾는 문제를 딥러닝을 통해 해결해보았습니다. Loss 값(실제값과 예측값의 차이)를 각각 w와 b로 편미분하여 역전파를 통해 경사 하강법으로 Loss값이 낮아지는 방향으로 파라미터를 업데이트해가는 과정을 배웠습니다. 그리고, 왜 딥러닝이 잘되고 성능이 좋은지 수학적으로 설명된 개념 Universal Approximators Theorm을 배웠습니다. 그리고, MLP의 기본구조도 배웠습니다.
2강 실습에서는 MNIST 손글씨 데이터를 MLP를 통해 학습하고 예측하는 과정을 배웠습니다.
3️⃣ Optimization(최적화)
3강에서는 최적화(Optimization)과 관련된 용어와 다양항 최적화 기법, 규제(Regularization)방법을 배웠습니다. 먼저, 최적화의 주요 용어는 아래와 같습니다.
1. Genralization(일반화 성능): 학습 데이터 성능과 테스트 데이터 성능의 차이를 Generailzation Gap이라고 하고, 이 Gap이 작을 수록 Generalization 성능이 좋다고 합니다.
2. Underfitting vs Overfitting: 언더피팅은 모델이 학습이 덜 되어서, 학습데이터도 못맞추고, 테스트 데이터도 못맞추는 것을 의미합니다. 오버피팅은 학습데이터만 달달 외워서 학습데이터는 다 맞추는데, 테스트 데이터에서 성능이 안좋게 나오는 것을 의미합니다.
3. Cross-validation: 학습 데이터안에서 Validation 데이터를 나눠 성능을 측정하며 학습하는 것을 의미합니다. K-fold Validation이 많이 쓰이며, 이는 학습 데이터를 K개로 나누어 1개씩 돌아가며 Validation data로 쓰는것을 의미합니다.
4. Bias and Variance: Variance(분산)은 출력이 얼마나 퍼져있는지를 의미합니다. 분산이 크다면 예측값과 타겟값 사이의 분포가 퍼져있습니다. Bias(편향)은 예측값들이 타겟값과 얼마나 가까운지를 의미합니다. Bias가 작다면 예측값과 타겟값이 가깝다는 것을 의미합니다.
5. Bootstrapping(부트스트래핑): 데이터를 랜덤 샘플링해서 여러 서브 데이터셋으로 나눈뒤, 여러 모델로 학습하고 합쳐서 예측하는 것입니다.
6. Bagging(배깅) vs Boosting(부스팅): 배깅은 부트스트래핑해서 여러 모델의 결과를 평균 내서 예측하는 것을 의미합니다. 부스팅은 여러 weak learner 모델들을 Sequential 하게 연결해서 하나의 strong learner를 만드는 것을 의미합니다.
Gradient Descent(경사 하강법)을 진행하는 다양한 메소드들, 즉 최적화 기법들은 아래의 이미지로 요약될 수 있습니다.
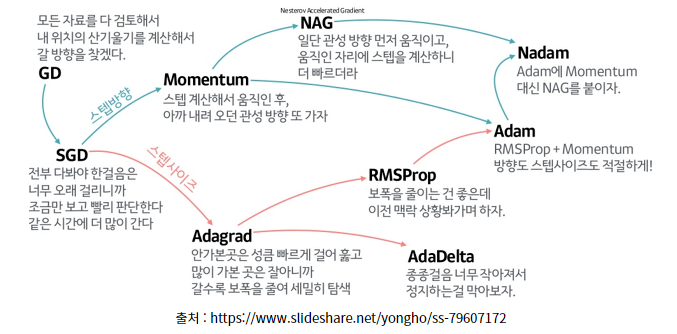
요즘은 Adam을 많이 사용합니다.
다음으로는 규제(Regularization) 방법론들을 살펴보겠습니다.
1. Early Stopping: Validation 에러가 증가하기 시작하면 멈추는 것입니다.
2. Parameter norm penalty(Weight Decay): 부드러운 함수일 수록, Generalization 성능이 좋을 것이다라는 가정하에, 파라미터가 너무 커지지 않게 하는 패널티를 의미합니다.
3. Data Augmentation(데이터 증강): 이미지 데이터의 경우, 라벨이 바뀌지 않는 한도내에서 데이터를 변환(회전, 확대/축소 등)시켜 데이터를 증강시키는 것을 의미합니다.
5. Noise Robustness: 입력 데이터에 노이즈를 막 집어넣습니다. Data Augmentation이랑 비슷하지만, 노이즈를 단순히 입력 데이터에만 넣는게 아니라, 뉴럴 네트워크의 Weight에도 넣습니다.
6. Label Smoothing: 데이터 2개를 뽑아서 섞어주는 것을 의미합니다. 예를 들어, 이미지 분류에서는 라벨이 다른 두 데이터를 섞어 분류가 되는 Decision Boundary를 부드럽게 해주는 효과가 있습니다.
7. Dropout: 학습시, 뉴럴 네트워크의 Weight를 랜덤하게 0으로 바꿔 학습되지 않도록 하는 것입니다. 오버피팅 방지와 매번 다른 형태의 노드로 학습하기 때문에 앙상블 효과도 낼 수 있습니다.
8. Batch Normalization(BN): 학습 시 미니배치를 한 단위로 데이터를 정규화 하는 것을 의미합니다. 데이터들이 정규화 됨으로써 Local Optimum의 골의 깊이가 낮아져 Local OPtimum에 빠질 수 있는 가능성을 낮춰주고, 데이터가 어느정도 일관된 Scale로 들어와 학습 안정화, 학습 속도 빨라짐 등의 효과가 있습니다.
3강 실습에서는 2차원에서 임의의 함수에 대해, Optimizer에 따라 얼마나 빨리 잘 맞추는지를 확인하는 실습을 했습니다.

4️⃣ CNN(Convolutional Neural Networks)
4강에서는 Convolution operation(합성곱) 연산과 기본적인 CNN의 구조에 대해서 배웠습니다. 합성곱연산은 f와 g라는 두 개의 함수가 있을 때, 두 함수의 합성곱 f * g를 의미합니다. 아래 그림을 보면, 전체 이미지 공간(I)와 커널(필터) K가 있을때 이 두 함수를 Convolution 한 것이 2D 이미지에서의 Convolution 연산을 의미합니다.

2D 이미지에서 Convolutino 연산의 결과는 필터에 따라 결과가 Blur 처리가 될 수 도있고, 강조, 경계선만 보이는 처리가 될 수 있습니다. CNN은 Convolution 연산과 Pooling(풀링) 연산을 통해 피처 정보를 추출하고, 마지막에 Fully Connected 레이어를 통해 Decision Making을 하는 네트워크를 의미합니다. Pooling(풀링)연산이란 특성맵을 다운샘플링 하여 특성 맵의 크기를 줄이는 연산을 의미합니다. Max Pooling이란 다운 샘플링 할 때, 특성맵을 풀링 커널이 돌면서 최대값만 추출하는 것을 의미합니다.
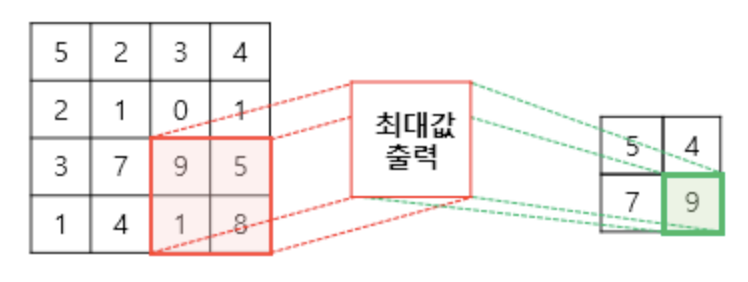
외에도, 필터가 움직이는 칸수인 Stride, 특성맵이 Conv나 Pooling 레이어를 통과할 때 경계선(테두리)도 인식할 수 있게 테두리 바깥으로 0을 채워넣는 Zero Padding 등을 하게 됩니다.
CNN 모델을 볼 때 중요하게 볼 것은 파라미터의 개수를 계산하는 방법입니다. 파라미터 개수는 Stride나 Padding에 상관없이 인풋 채널과 아웃풋 채널이 있을 때 Bias를 고려하여 아래와 같은 식으로 계산해 줍니다.

예를 들어, 아래 그림과 같이 입력 채널이 3개인 32 x 32 x 3 크기의 input이 있고, 5x5x3 커널(필터)을 사용하여 Conv 연산을 하고, 그 결과 28 x 28 x 6의 output이 나왔다면, 필요한 파라미터의 개수는 아래와 같습니다.

num_parameters = (K * K) * Cin * Cout + Cout = (5 * 5) * 3 * 6 + 6 = 456
5️⃣ Modern CNN
5강에서는 연도별 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)에서 뛰어난 성능을 보인 5개 모델의 주요 아이디어와 구조를 배웠습니다.
1. AlexNet (2011 - 1st) : 8레이어로 2개의 GPU로 나눠 학습한 CNN. ReLu 활성화 함수를 사용했고, 데이터 증강과 Dropout을 사용했습니다. 지금 보면 데이터 증강, Dropout은 당연히 쓰는 것이지만 당시에는 흔치 않은 것으로, 기준을 잡아준 것으로 볼 수 있습니다.
2. VGGNet(2014 - 2nd) : 3x3 필터만 사용했다는게 특징입니다. 3x3필터를 2번 사용하면 5x5를 1번 사용한 것과 같은 효과를 갖지만, 3x3을 2번 사용한것이 더 깊고, 파라미터 개수는 더 적다는 장점이 있습니다. 깊고, 파라미터가 더 적을 수록 성능이 좋다는 경향과 일치합니다.
3. GoogleNet (2014 - 1st): 비슷한 네트워크 구조가 전체 구조안에서 반복되어 NiN(Network in Network)구조를 사용했습니다. 이렇게 반복되는 구조를 Inception Block이라고 하며, 주요 특징은 1x1 Conv 연산을 통해 채널을 줄임으로써 파라미터 수를 줄였습니다.
4. ResNet (2015 - 1st): 파라미터 개수가 많고, 네트워크가 깊으면 학습 자체가 잘 안되어 버리는 근본적인 문제를 해결한 모델입니다. 기존 값을 활성화 함수 통과전에 더해주는 skip connection(Identity Map) 과정을 추가함으로써 네트워크가 깊어져도 학습이 잘 되도록 하였습니다.
5. DenseNet (2016) : ResNet에서 skip connection으로 x+f(x)를 했다면, 두 값이 섞이니까 [f(x), x]로 concatenation(이어 붙이기)를 했습니다. 그러면 아래 그림 Dense Block 1의 화살표처럼 Concatenation에 의해 파라미터 개수도 기하급수적으로 커지므로, 중간 중간에 1x1 Conv 연산을 통해 채널 수를 확 줄여주는 연산을 넣어줬습니다.
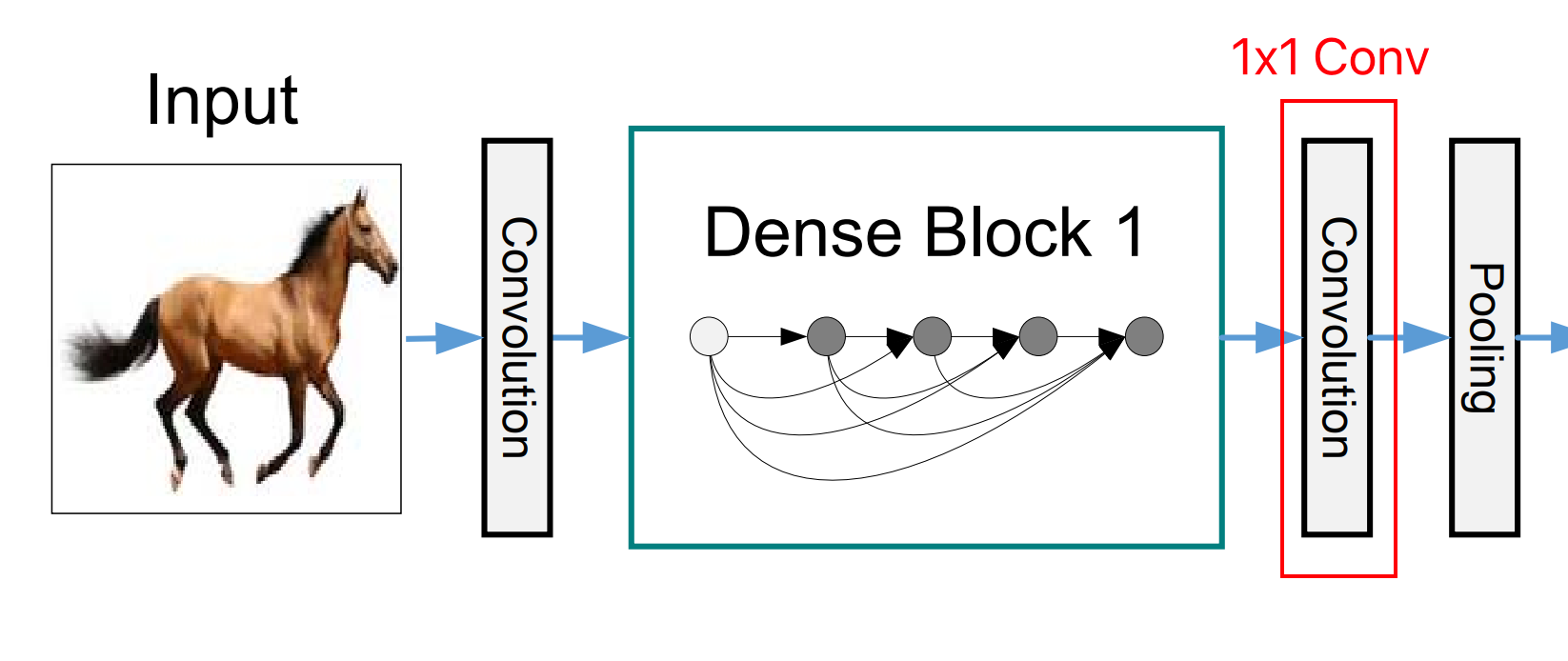
6️⃣ Computer Vision Applications
6강에서는 Computer Vision에서 CNN을 이용한 Semantic Segmentation과 Object Detection에 대해서 배웠습니다. Semantic Segmentation이란, 아래 이미지처럼 어떤 이미지가 있을 때, 이미지를 픽셀마다 분류하는 문제를 의미합니다.

보다싶이, 자율주행에 많이 사용됩니다. Semantic Segmentation의 원리는 Fully Connected Layer(Dense Layer)를 없애고, 그 부분을 Conv 레이어로 바꿔 이미지를 히트맵 형태로 구분할 수 있게되는 것 입니다. 이를 Convolutionalization이라고 합니다. 즉, Convolutionalization을 통해 Conv연산으로만 이루어진 Fully Convolutional Network(FCN)가 되면 주어진 이미지를 히트맵화 시킬 수 있습니다. 아래를 보면 개, 고양이 사진이 있을 때, 고양이부분을 히트맵 형태로 구분할 수 있습니다.

그에 반해, Object Detection은 이미지 내부에서 픽셀별로 분류하는 게 아니라, Bounding Box로 분류하는 것을 의미합니다. R-CNN 부터 SPPNet, Fast R-CNN, Raster R-CNN 그리고 YoLo까지 동작원리를 간단히 배웠습니다. 현재는 YOLO가 많이 쓰이는데, 이미지가 들어오면 SxS Grid로 나눈다. 그래서, 이미지 안에 바운딩 박스가 5개있다고 가정하고, SxS 그리드안에서 박스와, 분류를 동시에 진행한다. 그래서 텐서의 관점에서 보면 "SxS 그리드가 사용되고 x 5개의 바운딩 박스(B5)에 분류되는 클래스 C개가 더해진값"이 사용된다.
즉, SxS(B5+C)개의 채널을 갖는 텐서를 만드는게 욜로다.

7️⃣ RNN(Recurrent Neural Networks)
7강에서는 Sequential data와 이를 이용한 Sequential Model의 정의와 종류에 대해서 배웠습니다. Sequential Data는 순서가 있는 데이터로, 오디오, 비디오, 텍스트 등을 의미합니다. Sequential Model은 순서가 있는 데이터를 처리하기 위한 모델로, 연속적인 입력으로부터 연속적인 출력을 생성하는 모델을 의미합니다. 처음에 입력에 있어서 과거 데이터가 늘어날 수록 봐야 하는 데이터가 계속 증가하는 문제가 있었습니다. 이를 해결하기 위해 나온게 Autoregressive Model(자기회귀 모델)로 과거 데이터 보는 양을 Fix 시켜버리는 방법입니다. 예를 들어, 현재 시점에서 과거 3개의 데이터만 보는 것으로 Fix 시켜서 시간이 지나도 계속 과거 3개만 보는 모델입니다. 대표적인 예로 Markov Model이 있습니다. 하지만, 과거 데이터 보는 양을 Fix 시켜버리면 과거의 엄청 중요한 데이터는 바로 누락되어버리는 문제가 발생합니다. 이를 해결하기 위해 나온게 RNN(Recurrent Neural Network)입니다. RNN의 동작원리는 연속적으로 들어오는 데이터 입력에 대해, 마치 재귀적으로, 가중치가 계산되어 다음 입력에 적용되고, 또 가중치가 계산되어 다음 입력에 적용되는 식으로 동작합니다. RNN을 시간순으로 쭉 풀면 아래 그림의 오른쪽 처럼 x1, x2, ... xT 까지를 Input으로 하는 선형으로 길쭉한 하나의 네트워크라고 볼 수 있습니다.

하지만, RNN은 짧은 과거에 대해서는 가중치 반영이 잘되는 (Short Term Dependencies)가 있지만, 오래된 데이터에 대해서는 가중치가 소멸해버려 Long Term Dependencies는 잡지 못하는 문제가 있습니다. 이를 해결하고자 나온게 LSTM(Long Short Term Memory)입니다. 핵심은 Cell State 연산에서 과거의 정보를 잘 요약해서 중요한 정보와 중요하지 않은지를 판단하는 연산이 있다는 점입니다. 이 연산 덕분에 매우 예전 데이터라도 중요하다면 기억하게 되어 Logn Term Dependencies를 갖게 되었습니다. LSTM의 동작 원리를 보면, 3개의 게이트 Forget Gate, Input Gate, Output Gate로 이루어져있습니다.
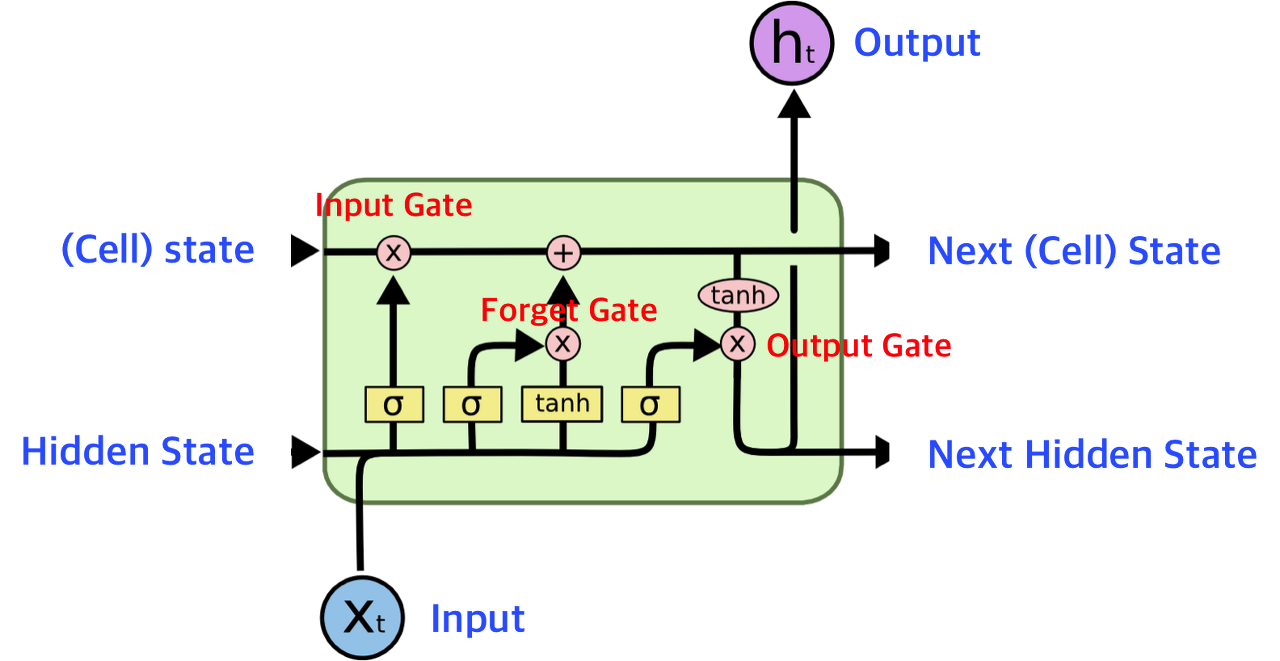
게이트를 중심으로 간단히만 보겠습니다.
1. Forget Gate: 어떤 정보를 버릴지 결정합니다. 현재 입력과 과거의 Hidden State를 입력받아 가중치 곱하고 활성함수를 통해 웨이트를 조절하여 버릴 정보를 결정합니다.
2. Input Gate: 현재 입력으로 받은 정보중 어떤 정보를 저장할지 결정합니다.
3. Output Gate: Forget Gate와 Input Gate를 통과한 내용을 바탕으로 cell state를 업데이트하고, update된 cell state를 한번 더 조작해서, 출력할 값을 Output으로 내보냄과 동시에 다음 셀의 히든 스테이트로도 들어갑니다.
외에도, GRU(Gated Recurrent Unit)을 배웠습니다. LSTM과 차이점은 게이트가 2개만 있으며, Reset Gate가 LSTM의 Forget Gate와 비슷한 역할을 함과 동시에 Update Gate의 역할도 수행한다는 점입니다. LSTM보다 파라미터 개수는 적은데 수행하는 능력이 같아 성능이 더 좋은 편입니다.

7강 실습에서는 LSTM을 통해 MNIST의 숫자를 예측해보는 실습을 진행했습니다.
8️⃣ Transformer(트랜스포머)
8강에서는 Sequential Model의 한계와 이를 극복하기 위해 등장한 Transformer와 Encoder, Multi Head Attention을 배웠습니다. Sequential 모델링이 어려운 이유는 시퀀스에 대해 의미는 변하지 않지만, 다양한 변형이 이루어질 수 있고, 이 미묘한 차이를 모델이 파악하기 쉽지 않기 때문입니다. Transformer는 Attention을 통해 이 문제를 해결했습니다. 트랜스포머는 Encoding, Decoding 과정을 거치는데 Attention 값은 Encoding 과정에서 계산됩니다. 간단히 요약하면, 입력으로 들어온 문장의 개별 단어 임베딩 벡터에 대해, Query, Key, Value라는 벡터로 나누어 각 단어별로 모든 단어에 대해 Attention Score를 계산하여, 가장 관련있는 단어를 파악합니다. 이를 Self Attention 구조라고 합니다. 트랜스포머 하나 하나를 Head 라고 하는데, 보통 MHA(Multi Head Attention)으로 여러 트랜스포머를 병렬적으로 사용합니다. single-head attention은 각 단어별로 하나의 연관성만 파악이 되는데, MHA는 이를 여러 초기 조건으로 학습시킴으로써 더 많은 연관성을 고려할 수 있기 때문입니다.
9️⃣ Generative Models(생성모델) Part1
9강에서는 Generative 모델이 무엇인지를 배웠습니다. Generative model(생성 모델)이란 주어진 학습 데이터를 이용해 학습 데이터의 분포를 따르는 유사한 데이터를 생성하는 모델입니다. 생성 모델은 아래 그림처럼 크게 2가지로 분류되며, 학습 데이터의 분포를 안 상태에서 생성하는 Explicit 모델과 학습 데이터의 분포를 잘 모르고 생성하는 Implicit 모델로 나뉩니다.
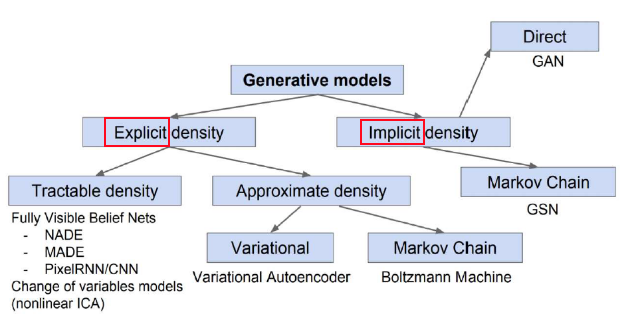
학습 데이터 분포에 대해, 조건부확률을 모두 계산하는건 파라미터수가 너무 많습니다. 각 데이터가 모두 독립적(Independence)이라고 가정하면 파라미터 수는 줄지만 유의미한 분포를 추론하긴 어렵습니다. 그래서 그 중간의 Conditional Independence 방법을 이용하여 파라미터 수도 적당하고, 어느정도 유의미한 분포를 추론할 수 있습니다.
Explicit Model중 AR(AutoRegressive) 모델이 있습니다. 자기 회귀 모델이라고도 불립니다. 샘플링이 쉽고, 새로운 입력에 대한 Joint Distribution을 쉡가 구할 수 있으며, Discrete(이산)과 Continuos(연속)을 모두 고려할 수 있다는 장점이 있지만, 한 번에 뉴럴네트워크를 통과해야 하기 때문에 병렬 연산이 안된다는 단점이 있습니다.
🔟 Generative Models(생성모델) Part2
10강 에서는 실제로 사용되는 Generative Model 들을 배웠습니다. Genrative Model을 풀 수 있는 비교적 쉬운 방법론인 MLE(Maximum Likelihood Learning)을 배웠습니다. 그리고, 잠재 변수 모델(Latent Variable Model)인 VA(Variational AUtoencoder)와 VI(Variational Inference) 그리고, VAE(Variational Auto-Encoder)의 목적식에 대해 간단히 배웠습니다.
다음으로는 유명한 GAN(Generative Adversarial Networks)를 배웠습니다. Generator(생성기)와 Discriminator(판별기)가 서로 적대적으로 학습하는 방법입니다. 다음으로, Diffusion Model에 대해 배웠습니다. 요즘 유명한 DALL-E2의 성능이 정말 신기하게 와닿았습니다.
2) Data Visualization(데이터 시각화)
1️⃣ Introduction to Visualization(시각화 소개)
1강에서는 아래 3가지를 중점적으로 다룹니다.
- 시각화 강의 소개
- 시각화 요소의 상태 (점, 선, 면)
- Python과 Matplotlib
2️⃣ 기본 차트의 사용
2강에서는 아래 3가지를 중점적으로 다룹니다.
- Bar Plot 사용하기 - 기본 Bar Plot, Multiple Bar Plot, Stacked Bar Plot, Percentage Bar Plot, Grouped Bar Plot
- Line Plot 사용하기 - 추세, 간격, 보간, 이중 축 사용 등
- Scatter Plot 사용하기 - 두 피처의 관계 보기
3️⃣ 차트의 요소
3강에서는 아래 4가지를 중점적으로 다룹니다.
- Text 사용하기 (Title, Legend, Ticks, Text, 화살표 사용)
- Color 사용하기 (범주형, 연속형, 발산형 색상 및 대비 팁)
- Facet 사용하기 (화면에 대한 분할)
- More Tips (Grid, Line & Span, Settings - plt.rc, theme)
2. 피어 세션
1) 일반
이번주에는 강의, 과제에 대해 서로 질문도 심도있게했습니다. 무엇보다 같은 팀끼리 코딩테스트 스터디도 진행하고, 면접 질문 스터디도 같이 하게되었습니다. 둘 다 제가 제안한 스터디지만 모두 좋다고 하셨고, 노션과 구글 시트를 이용해 시스템을 만들어 두니 모두 적극적으로 참여해주셔서 너무 기뻤습니다. 특히 저는 수학 수식이 너무 어렵게 느껴졌는데, 질문 하면 수식 관련해서 다들 깊게 이해하고 계셔서 친절히 설명해주셔서 너무 좋았습니다.
2) 코딩테스트 스터디
이번 주 부터 코딩테스트 스터디를 시작했습니다. Greedy 알고리즘을 각자 1문제씩 풀어와서 발표했고, 모두 풀고 엑셀 시트에 체크했습니다.
3) 면접 질문 스터디
이번 주 면접 스터디 주제는 Gradient Descent(경사 하강법)입니다. 제가 준비한 주제는 왜 Neural Network에서는 꼭 Gradient Descent를 써야할까 였습니다. 핵심은 주어진 데이터에 대해 분포를 모른 상태로 추정해야 하기 때문에, 목적식(Objective Function)을 최적화 하는 방법의 Gradient Descent가 분포를 근사하는 가장 효율 적인 방법이라는 점입니다. 외에 다른 분들은 GD중 때때로 loss가 증가하는 이유, BackPropagation의 원리 등을 준비해서 발표했습니다.
4) 한 주 회고

3. 그 외 이벤트들
1) 멘토링
이번주에는 면접 질문이 어떤식으로 이루어지는지 멘토링해주셨습니다. 특히 LSTM, GRU에서 활성함수로 tanh를 쓰는 이유에 대해서 다음 멘토링까지 생각해보라고 하셨습니다. 그리고, 차원을 쉽게 다루는 팀도 주셨습니다. 핵심은 특정 변수 x가 4차원이다 하면 x[:, :, :, :]를 찍고 내부적인 차원을 조절하면 조절이 쉽다는 팁이였습니다.
2) 마스터클래스(최성준 교수님 이야기)
고려대학교에서 로봇과 인공지능을 접목한 랩실에 계시는 최성준 교수님의 이야기를 들었습니다. 회사를 다니다가, 느지막히 대학원을 가셨고, 그 때 생활의 힘든점을 많이 말씀해주셨습니다. 그리고 우연한 계기로 커뮤니티에 들어가서 거기서 강의에 대한 여러가지 커리어가 만들어진 얘기를 해주셨습니다. 가만히 얘기를 듣고있으니, 커리어의 방향성을 너무 내 생각으로만 만들어가지 말고, 해보고싶은 것, 도전하고 싶은 것에 도전해가다 보면, 재미있는 기회들이 오게되고 거기서 최선을 다하다 보면, 커리어가 재미있고 흥미롭게 만들어진다는 느낌을 받았습니다. 그리고 교수가 되면 대학원생이 논문을 읽어줘서 논문을 안 읽게 된다고 농담하신게 정말 웃겼습니다. 나중에 대학원 진학에 필요한 능력이 뭘지 질문할 때, 댓글창에 논문 읽어주는 능력이라고 다들 드립을 치시던게 떠오릅니다.
3) 오피스아워(ViT & AAT 심화과제 해설)
이번 심화과제는 ViT(Vision Transformer) 구현과 AAE(Adversarial Auto-Encoder) 구현 과제였습니다. ViT 과제는 정말 흥미로웠던 게, 이미지를 조각조각 내고 Positional Encoding을 거쳐 해당 이미지의 레이블을 예측하는 모델을 트랜스포머 기반으로 구현되었을 때 성능이 매우 좋았다는 점 입니다. 이미지를 가로세로로 49등분하고, 각 1/49 조각 끼리의 관계를 통해 해당 이미지가 어떤 라벨을 가졌는지 예측한 다는점이 정말 신기했습니다. AAE라는 생성 모델을 통해 이미지를 예측하는 실습 역시 신기했습니다. 아직 생성모델의 원리를 제대로 이해하지 못한게 좀 아쉽습니다.
Reference)
1. 네이버 부스트캠프 Ai tech 4기
2. Max Pooling : https://wikidocs.net/62306
3. 파라미터 개수 계산 : https://bio-info.tistory.com/manage/newpost/190?type=post&returnURL=https%3A%2F%2Fbio-info.tistory.com%2F190
4. Conv Parameter 개수: cs231n 강의
5. DenseNet 이미지 : http://arxiv.org/abs/1608.06993
6. Semantic Segmantation: https://www.researchgate.net/figure/Example-of-2D-semantic-segmentation-Top-input-image-Bottom-prediction_fig3_326875064
7. YOLO : https://arxiv.org/abs/1506.02640
8. RNN의 구조: https://velog.io/@yuns_u/%EC%88%9C%ED%99%98-%EC%8B%A0%EA%B2%BD%EB%A7%9DRNN-Recurrent-Neural-Network
9. LSTM 구조: https://www.edwith.org/downloadFile/fileDownload?attachmentId=23325&autoClose=true
10. GRU 구조: https://wooono.tistory.com/242
'Data Science & Analysis > 부스트캠프 Ai tech 4기' 카테고리의 다른 글
| [부스트캠프 AI tech 4기] week 5 회고 📝 - 추천 시스템 심화 & 데이터 시각화(6~7) (0) | 2022.10.22 |
|---|---|
| [부스트캠프 AI tech 4기] week 4 회고 📝 - 추천 시스템과 데이터 시각화(4~5) (0) | 2022.10.19 |
| [부스트캠프 AI tech 4기] week 2 회고 📝 - Pytorch (0) | 2022.10.10 |
| [부스트캠프 AI tech 4기] 온보딩 키트 (0) | 2022.10.04 |
| [부스트캠프 AI tech 4기] week 1 회고 📝 - Python & AI Math (5) | 2022.09.25 |